Il campo dell'informatica è vasto e in continua evoluzione, con numerose aree che richiedono sviluppo e arricchimento. Tra queste, la gestione e l'organizzazione dei dati attraverso i database rappresentano un pilastro fondamentale. Questo articolo si concentrerà in dettaglio sul modello relazionale, uno dei paradigmi più diffusi e influenti nella progettazione di database, esplorandone i principi, le componenti chiave e le implicazioni pratiche.
Comprendere il Modello Relazionale
Il modello relazionale, introdotto da Edgar F. Codd nel 1970, rappresenta il database come una raccolta di relazioni. In termini più semplici, una relazione è essenzialmente una tabella composta da righe e colonne. Ogni riga all'interno di una tabella rappresenta un'entità o un record, mentre ogni colonna, nota come attributo, descrive una proprietà specifica di quell'entità. Il nome della tabella e i nomi delle colonne sono cruciali per interpretare il significato dei dati contenuti in ogni riga, fornendo un contesto semantico essenziale.
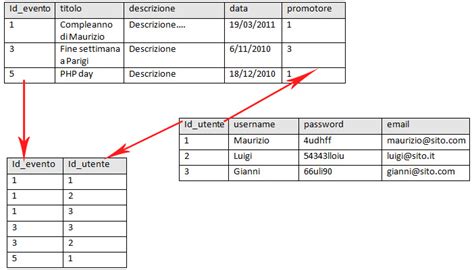
L'intera struttura dati viene quindi vista come un insieme di queste tabelle interconnesse. Questa rappresentazione tabellare è una delle caratteristiche distintive del modello relazionale, distinguendolo da altri approcci precedenti come il modello gerarchico o di rete. La sua forza risiede nella sua semplicità concettuale e nella sua capacità di rappresentare dati complessi in modo strutturato e facilmente gestibile.
Componenti Fondamentali del Modello Relazionale
Per una comprensione approfondita del modello relazionale, è necessario esaminare i suoi elementi costitutivi:
Tabelle (Relazioni)
Come accennato, le tabelle sono l'unità fondamentale di memorizzazione nel modello relazionale. Ogni tabella è composta da righe e colonne.
- Righe (Tuple): Ogni riga in una tabella è chiamata tupla o record. Rappresenta una singola istanza di un'entità. Ad esempio, in una tabella "Clienti", ogni riga conterrebbe le informazioni di un singolo cliente. L'insieme di tutte le tuple in un dato momento costituisce un'istanza di relazione.
- Colonne (Attributi): Ogni colonna in una tabella è definita come un attributo. Gli attributi rappresentano le proprietà o le caratteristiche delle entità memorizzate nella tabella. Ogni attributo ha un nome univoco all'interno della tabella e un dominio di valori specifici che può assumere. Ad esempio, nella tabella "Clienti", gli attributi potrebbero essere "CustomerID", "Nome", "Cognome", "Indirizzo", "Email".
Domini degli Attributi
Il dominio di un attributo definisce l'insieme dei valori possibili che quell'attributo può assumere. Ad esempio, il dominio dell'attributo "Età" in una tabella "Utenti" potrebbe essere l'insieme di tutti i numeri interi positivi inferiori a 150. Il rispetto dei domini è fondamentale per garantire la validità e la coerenza dei dati.
Chiavi
Le chiavi svolgono un ruolo cruciale nell'identificazione univoca delle tuple e nella definizione delle relazioni tra tabelle.
- Chiave Primaria: Un attributo (o un insieme di attributi) che identifica in modo univoco ogni riga (tupla) all'interno di una tabella è chiamato chiave primaria. Ogni tabella dovrebbe avere una chiave primaria. Ad esempio, "CustomerID" nella tabella "Clienti" è un tipico esempio di chiave primaria, poiché ogni cliente ha un ID univoco. La chiave primaria non può contenere valori nulli e ogni suo valore deve essere distinto.
- Chiave Esterna: Una chiave esterna è un attributo (o un insieme di attributi) in una tabella che fa riferimento alla chiave primaria di un'altra tabella (o della stessa tabella). Le chiavi esterne sono il meccanismo principale attraverso cui vengono stabilite le relazioni tra tabelle nel modello relazionale. Permettono di collegare dati correlati distribuiti su diverse tabelle. Ad esempio, in una tabella "Ordini", un attributo "CustomerID" potrebbe essere una chiave esterna che fa riferimento alla chiave primaria "CustomerID" nella tabella "Clienti", collegando ogni ordine al cliente che lo ha effettuato.
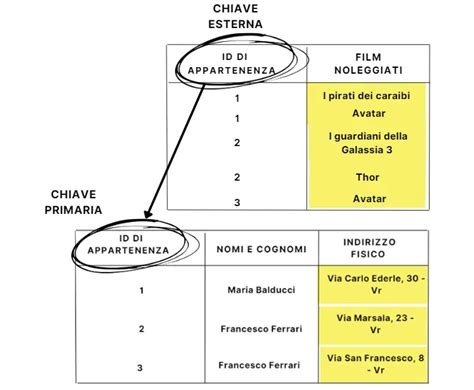
Integrità Relazionale
L'integrità relazionale si riferisce all'insieme di regole e vincoli che garantiscono la correttezza, la coerenza e l'affidabilità dei dati in un database relazionale. Questi vincoli assicurano che le operazioni sui dati non portino a stati incoerenti. I principali tipi di vincoli di integrità includono:
Integrità del Dominio
Questo vincolo specifica che i valori di ciascun attributo devono appartenere al suo dominio definito. Ad esempio, se l'attributo "Data di Nascita" ha un dominio di date valide, il sistema dovrebbe impedire l'inserimento di una stringa non valida o di una data inesistente.
Integrità delle Entità
Questo vincolo si applica alle chiavi primarie. Assicura che ogni tupla in una relazione sia univocamente identificabile. Ciò significa che la chiave primaria non può contenere valori nulli e che ogni valore della chiave primaria deve essere unico all'interno della tabella. Se una tupla viene rimossa, questo vincolo non viene violato, ma le operazioni che potrebbero portare a chiavi duplicate vengono impedite.
Integrità Referenziale
L'integrità referenziale è un concetto fondamentale legato all'uso delle chiavi esterne. Si basa sul principio che una chiave esterna deve fare riferimento a una chiave primaria esistente in un'altra tabella (o nella stessa tabella). Questo vincolo garantisce che non si creino "riferimenti orfani", ovvero che una tupla in una tabella non faccia riferimento a una tupla in un'altra tabella che non esiste più.
Ad esempio, se un cliente viene eliminato dalla tabella "Clienti", l'integrità referenziale può imporre azioni specifiche sulle righe correlate nella tabella "Ordini" (come l'eliminazione automatica degli ordini associati, la loro modifica per indicare un cliente nullo, o il blocco dell'eliminazione del cliente se esistono ordini associati).
I vincoli di integrità referenziale
Linguaggi di Interrogazione Relazionale: SQL
Per interagire con i database relazionali, è indispensabile un linguaggio di interrogazione. Il linguaggio standard de facto per i database relazionali è SQL (Structured Query Language). SQL è un linguaggio dichiarativo che consente agli utenti di creare, manipolare e interrogare i dati in modo efficiente.
Con SQL è possibile eseguire una vasta gamma di operazioni, tra cui:
- Definizione dei Dati (DDL - Data Definition Language): Creare, modificare ed eliminare tabelle, indici e altre strutture del database (
CREATE TABLE,ALTER TABLE,DROP TABLE). - Manipolazione dei Dati (DML - Data Manipulation Language): Inserire, aggiornare, eliminare e recuperare dati dalle tabelle (
INSERT,UPDATE,DELETE,SELECT). - Controllo dei Dati (DCL - Data Control Language): Gestire i permessi di accesso ai dati (
GRANT,REVOKE).
La potenza di SQL risiede nella sua capacità di esprimere interrogazioni complesse in modo relativamente semplice, permettendo di recuperare sottoinsiemi specifici di dati basati su criteri complessi e di aggregare informazioni da diverse tabelle attraverso operazioni di join.
Vantaggi del Modello Relazionale
Il successo e la pervasività del modello relazionale derivano da una serie di vantaggi significativi:
- Semplicità Concettuale: La rappresentazione dei dati in tabelle è intuitiva e facile da comprendere, anche per chi non è un esperto di database.
- Indipendenza Strutturale dei Dati: Il modello relazionale si concentra sulla rappresentazione dei dati e sulle loro relazioni, piuttosto che sulla struttura fisica di archiviazione. Questo significa che la struttura del database può essere modificata (ad esempio, aggiungendo o rimuovendo colonne) senza necessariamente influenzare le applicazioni che accedono ai dati, a condizione che le interrogazioni rimangano compatibili. Questa è una forma di indipendenza logica dei dati.
- Rigore Matematico: Il modello relazionale è basato sulla teoria degli insiemi e sulla logica matematica, il che fornisce una solida base teorica per la sua progettazione e implementazione. Questo rigore contribuisce alla coerenza e all'affidabilità del sistema.
- Flessibilità e Potenza di Interrogazione: SQL, il linguaggio standard per i database relazionali, offre una notevole flessibilità e potenza nell'estrazione e manipolazione dei dati. È possibile formulare interrogazioni complesse per rispondere a domande specifiche sui dati.
- Riduzione della Ridondanza dei Dati: Attraverso la normalizzazione, è possibile progettare schemi di database relazionali che minimizzano la duplicazione dei dati, migliorando l'efficienza dello storage e riducendo il rischio di incoerenze.
- Facilità di Manutenzione: Grazie alla sua struttura ben definita e alla disponibilità di strumenti standardizzati, i database relazionali sono generalmente più facili da mantenere, aggiornare e gestire rispetto a modelli più complessi o proprietari.
Svantaggi e Limitazioni
Nonostante i suoi numerosi vantaggi, il modello relazionale presenta anche alcune limitazioni, specialmente in contesti moderni:
- Scalabilità Orizzontale: Tradizionalmente, i sistemi di database relazionali sono stati progettati per scalare verticalmente (aumentando la potenza di un singolo server). Scalare orizzontalmente (distribuendo il carico su più server) può essere complesso e costoso, sebbene siano stati fatti progressi significativi in questo senso.
- Gestione di Dati Non Strutturati o Semi-strutturati: Il modello relazionale è ottimale per dati strutturati. La gestione di grandi volumi di dati non strutturati (come testi liberi, immagini, video) o semi-strutturati (come JSON, XML) può essere meno efficiente rispetto a database NoSQL specificamente progettati per tali scopi.
- Complessità della Normalizzazione: Sebbene la normalizzazione sia un vantaggio per ridurre la ridondanza, un eccessivo livello di normalizzazione può portare a un gran numero di tabelle e a interrogazioni complesse che richiedono molti join, potenzialmente impattando le prestazioni.
- Mappatura Oggetto-Relazionale (ORM): La transizione tra il paradigma orientato agli oggetti (comune nella programmazione moderna) e il modello relazionale tabellare può creare una "impedenza" che richiede l'uso di Object-Relational Mappers (ORM) per facilitare la conversione dei dati.
Applicazioni del Modello Relazionale
Il modello relazionale è alla base di innumerevoli applicazioni in quasi tutti i settori:
- Sistemi di Gestione Bancaria: Gestione di conti correnti, transazioni, clienti.
- Sistemi di Gestione Inventario: Tracciamento di prodotti, ordini, fornitori.
- Sistemi di Gestione delle Risorse Umane (HRM): Archiviazione di dati sui dipendenti, stipendi, benefit.
- Piattaforme di E-commerce: Gestione di cataloghi prodotti, ordini, informazioni sui clienti.
- Sistemi di Prenotazione: Gestione di voli, hotel, appuntamenti.
- Applicazioni Web e Mobili: Quasi tutte le applicazioni che richiedono la memorizzazione e il recupero di dati strutturati utilizzano internamente un database relazionale.
La vasta adozione di database relazionali come MySQL, PostgreSQL, Oracle Database, SQL Server e SQLite testimonia la robustezza e l'efficacia di questo modello.
Il Futuro del Modello Relazionale
Nonostante l'ascesa dei database NoSQL, il modello relazionale non mostra segni di declino. La sua solidità, la maturità della tecnologia e l'ampia base di competenze esistenti assicurano la sua continua rilevanza. Le innovazioni recenti nei sistemi di gestione di database relazionali si concentrano sul miglioramento della scalabilità, sull'integrazione con tecnologie NoSQL per carichi di lavoro ibridi e sull'ottimizzazione delle prestazioni per gestire volumi di dati sempre crescenti.
Il modello relazionale, con i suoi principi ben definiti di tabelle, attributi, chiavi e vincoli di integrità, rimane un pilastro fondamentale nell'architettura dei dati, offrendo un quadro robusto e affidabile per la gestione delle informazioni che alimentano il mondo digitale. La sua capacità di strutturare e interrogare dati in modo logico e coerente continua a renderlo una scelta privilegiata per una vasta gamma di applicazioni.
tags: #modello #relazionale #in #umpc