Un database è un insieme di informazioni (o dati) strutturate, generalmente archiviate elettronicamente in un sistema informatico. Di solito, il database viene controllato da un sistema DBMS (Database Management System). Si fa riferimento ai dati, al sistema DBMS e alle applicazioni associate come sistema di database, spesso abbreviato solo in database. I dati all'interno dei tipi più comuni di database attualmente in funzione vengono generalmente presentati in righe e colonne contenute in una serie di tabelle per garantire l'efficienza di elaborazione e query dei dati. Tali dati possono poi essere facilmente visualizzati, gestiti, modificati, aggiornati, controllati e organizzati.
SQL è un linguaggio di programmazione utilizzato da quasi tutti i database relazionali per eseguire query, manipolare e definire i dati, nonché fornire il controllo dell'accesso. Sviluppato per la prima volta negli anni '70 in IBM con l'importante contributo di Oracle, che ha determinato l'implementazione dello standard SQL ANSI, SQL è stato fonte di ispirazione per numerose estensioni create da aziende quali IBM, Oracle e Microsoft. Sebbene SQL sia ampiamente utilizzato ancora oggi, nuovi linguaggi di programmazione stanno iniziando a fare il loro ingresso sul mercato.
L'Evoluzione dei Sistemi di Gestione dei Dati
La crescita evolutiva dei database è stata notevole dai suoi inizi nei primi anni '60. I sistemi originali utilizzati per memorizzare e manipolare i dati erano i database dedicati alla navigazione, quali il database gerarchico (che si basava su un modello ad albero e consentiva solo una relazione di tipo uno-a-molti) e il database di rete (un modello più flessibile in grado di permettere più relazioni). Sebbene semplici, questi primi sistemi mancavano di flessibilità.
Negli anni '80, i database relazionali acquisirono notorietà, seguiti dai database orientati agli oggetti negli anni '90. Più di recente, sono comparsi i database NoSQL in risposta alla crescita di Internet e per soddisfare l'esigenza di maggiore velocità ed elaborazione dei dati non strutturati.
I database e i fogli di calcolo (ad esempio, Microsoft Excel) sono entrambi soluzioni pratiche per archiviare le informazioni. I fogli di calcolo sono stati progettati in origine per un unico utente e le loro caratteristiche rispecchiano tale intento. Rappresentano una soluzione ideale per utenti singoli o in numero limitato che non devono eseguire molte delle complicatissime procedure di manipolazione dei dati. I database, invece, sono destinati a contenere insiemi molto più estesi di informazioni organizzate, presenti talvolta in massicce quantità. I database consentono a più utenti contemporaneamente di accedere ai dati ed eseguirne query in modo rapido e sicuro mediante una logica e un linguaggio estremamente complessi.
I Database Relazionali: Fondamenti e Struttura
Esistono molti tipi diversi di database. I database relazionali assumono un ruolo predominante negli anni '80. Gli elementi di un database relazionale sono organizzati sotto forma di set di tabelle composte da colonne e righe. Un database distribuito è composto da almeno due file presenti in sedi diverse. Un database NoSQL, o non relazionale, consente di archiviare e manipolare dati non strutturati e semi-strutturati, a differenza di quanto accade con un database relazionale che definisce come devono essere composti tutti i dati inseriti nel database. Database OLTP. Le tipologie menzionate rappresentano solo alcune delle diverse dozzine di tipi di database oggi in uso. Altri database meno comuni vengono personalizzati in base a funzioni scientifiche, finanziarie o di altro tipo estremamente specifiche.
Un database relazionale è un tipo di database di archiviazione che fornisce accesso a data points correlati tra loro. I database relazionali sono basati sul modello relazionale, un modo intuitivo e diretto di rappresentare i dati nelle tabelle. In un database relazionale ogni riga della tabella è un record con un ID univoco chiamato chiave.
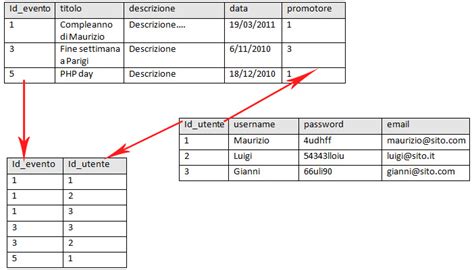
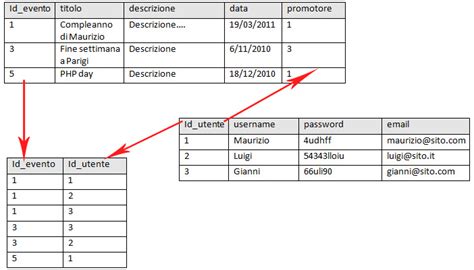
Ecco un semplice esempio di due tabelle che potrebbero essere utilizzate da una piccola azienda per elaborare gli ordini dei suoi prodotti. La prima è una tabella di informazioni sul cliente, quindi ogni record include nome, indirizzo, dati di spedizione e fatturazione, numero di telefono e altre informazioni di contatto del cliente. Ogni bit di informazioni (ogni attributo) si trova nella colonna corrispondente e il database assegna un ID univoco (una chiave) a ciascuna riga. Queste due tabelle hanno solo una cosa in comune: la colonna ID (l'elemento chiave). È tuttavia grazie a questa colonna comune che il database relazionale può creare una relazione tra le due tabelle. Quindi, quando l'applicazione di elaborazione degli ordini dell'azienda invia un ordine al database, il database può consultare la tabella degli ordini del cliente, estrarre le informazioni corrette sull'ordine del prodotto e utilizzare l'ID cliente contenuto in quella tabella per cercare i dati di fatturazione e spedizione del cliente nella tabella delle informazioni del cliente.

Il modello relazionale implica che le strutture logiche dei dati (tabelle di dati, viste e indici) sono separate dalle strutture di storage fisico. Grazie a questa separazione, gli amministratori di database possono gestire lo storage fisico dei dati senza compromettere l'accesso a tali dati come struttura logica. La distinzione tra logico e fisico si applica anche alle operazioni di database, che sono azioni chiaramente definite che consentono alle applicazioni di manipolare i dati e le strutture del database. Per garantire che i dati siano sempre accurati e accessibili, i database relazionali seguono regole di integrità specifiche.
Nei primi anni dell'esistenza dei database ogni applicazione archiviava dati nella propria struttura unica. Qualora fosse necessario creare applicazioni per utilizzare tali dati, gli sviluppatori avevano bisogno di conoscere numerosi dettagli sulla struttura dei dati specifica, al fine di trovare i dati necessari. Queste strutture dati erano inefficienti, difficili da gestire e da ottimizzare per offrire buone performance delle applicazioni. Il modello dati relazionale ha fornito una modalità standard di rappresentare e interrogare i dati che potrebbero essere utilizzati da qualsiasi applicazione.
Con il passare del tempo, è emerso un altro punto di forza del modello relazionale, poiché gli sviluppatori hanno iniziato a utilizzare il linguaggio SQL (Structured Query Language) per scrivere dati in un database ed eseguirvi query. Per molti anni, SQL è stato ampiamente utilizzato come linguaggio per le query di database. Basato sull'algebra relazionale, SQL offre un linguaggio matematico internamente coerente che semplifica il miglioramento delle performance di tutte le query di database.
Il semplice ma potente modello relazionale viene utilizzato da organizzazioni di ogni tipo e dimensione per un'ampia varietà di esigenze di informazione. I database relazionali vengono utilizzati per tracciare gli inventari, elaborare transazioni di e-commerce, gestire enormi quantità di informazioni sui clienti mission-critical e molto altro. I database relazionali sono utilizzati sin dagli anni '70. Il modello relazionale è il migliore modo per mantenere la coerenza dei dati tra applicazioni e copie di database (i cosiddetti casi). Ad esempio, quando un cliente deposita denaro presso un bancomat e poi controlla il saldo del conto sul cellulare, si aspetta di vedere l'importo depositato immediatamente riflesso nel saldo del conto aggiornato. Per altri tipi di database è difficile mantenere questo livello di coerenza in modo rapido con grandi quantità di dati. Alcuni database recenti, come NoSQL, possono garantire solo la coerenza finale.
Database: Panoramica Completa (o quasi...)
Oracle Database: Un Pilastro nel Mondo Relazionale
Oracle Database è un DBMS (Database Management System) relazionale sviluppato da Oracle Corporation. Si tratta di una delle piattaforme per basi di dati più diffuse al mondo, assieme a Microsoft SQL Server e MySQL (anche quest'ultimo è di proprietà di Oracle). Viene utilizzato per gestire database in aziende di dimensioni e settori disparati.
Istanza e Database in Oracle
Un'istanza Oracle è un insieme di processi/thread di background e un'area di memoria condivisa cui essi accedono; essa (la memoria) è il luogo in cui mantenere dati volatili e non persistenti che saranno poi scritti su disco. Un'istanza del database può esistere anche senza alcuno spazio di archiviazione su disco.
Il database, invece, è l'insieme dei dati e metadati che si decide di organizzare in maniera strutturata al fine di ricercare, elaborare e mettere a disposizione le informazioni oggetto di interesse; questi dati saranno scritti su file fisici specializzati in base alla funzione che svolgono: datafile, controlfile, redologs e tempfiles.
I due termini vengono talvolta usati in modo intercambiabile, ma abbracciano concetti molto diversi. La relazione tra di essi è che un database può essere montato ed aperto da molte istanze. Un'istanza può montare ed aprire un singolo database in qualsiasi momento. Infatti, un'istanza monterà ed aprirà al massimo un singolo database in tutta la sua vita.
Oracle Transparent Data Encryption (TDE)
TDE esegue la crittografia in modo trasparente dei dati ‘at rest’ nei database Oracle. Blocca i tentativi non autorizzati da parte del sistema operativo di accedere ai dati del database archiviati nei file, senza influire sul modo in cui le applicazioni accedono ai dati utilizzando SQL. TDE può crittografare interi tablespace dell'applicazione o colonne di tabelle ed è completamente integrato con il database Oracle. I dati crittografati rimangono crittografati nel database, sia che si tratti di file di tablespace dati, temporary tablespace, undo tablespace o altri file su cui Oracle Database fa affidamento, come i redologs. Inoltre, TDE può crittografare i backup di interi database (RMAN) e le esportazioni di Data Pump.
Oracle Database Security Assessment Tool (DBSAT)
Oracle Database Security Assessment Tool (DBSAT) fornisce raccomandazioni su come mitigare i rischi o le lacune di sicurezza identificate all'interno dei database Oracle. DBSAT profila lo stato di sicurezza e conformità dei database valutando lo stato corrente, inclusa la configurazione, rilevando inoltre i dati sensibili e altro ancora.
Oracle Backup con RMAN
Un backup in Oracle è una copia dei dati del database che può essere utilizzata per ripristinare il database in caso di perdita di dati o errori. La struttura fisica del database e il ruolo che ciascun elemento riveste nel processo di backup e recovery sono gli elementi che concorrono a determinare quali tecniche di backup e recovery utilizzare. I file e le altre strutture che compongono un database Oracle archiviano i dati e li proteggono da possibili guasti.
I backups possono essere suddivisi in due categorie:
- Backup fisici (RMAN): sono backup dei file fisici utilizzati per contenere i dati e per recoverare il database ossia datafile, controlfile e archived redolog. In definitiva, ogni backup fisico è una copia dei file che memorizzano le informazioni del database in un'altra posizione, su disco o su un dispositivo di archiviazione offline come una tape library.
- Backup logici (expdp): essi contengono i dati logici (tabelle, stored procedure, trigger…) esportati attraverso l’utility export di Oracle. Tali dati sono conservati in uno o più file binari (.dmp) e sono utilizzati per essere eventualmente reimportati nel database con l’utility import.
I backup fisici sono il fondamento di qualsiasi strategia di backup e ripristino.
Oracle Multitenant
Il Multitenant, introdotto a partire dalla versione 12c Release 1, permette di gestire in modo più efficace ed efficiente i database in gestione e le risorse hardware a disposizione.
Vantaggi e Svantaggi dei Database Relazionali
Impiegare database relazionali offre numerosi benefici. Il principale è rappresentato dalla capacità di creare informazioni significative unendo le tabelle. Ciò permette di comprendere le relazioni tra i dati, o come le tabelle si collegano. Gli analisti possono ordinare i risultati per data, nome o qualsiasi colonna.
Un altro beneficio è la sua flessibilità. SQL ha il suo linguaggio integrato per la creazione di tabelle chiamato Data Definition Language (DDL). Esso permette di aggiungere nuove colonne, aggiungere nuove tabelle, rinominare relazioni e fare altri cambiamenti anche mentre il database è in esecuzione e mentre le query sono in corso. Ciò consente di cambiare lo schema o il modo in cui si modellano i dati.
Essi inoltre eliminano la ridondanza dei dati. Le informazioni per un singolo cliente appaiono in un solo posto: una singola voce nella tabella dei clienti. La tabella degli ordini ha solo bisogno di memorizzare un collegamento alla tabella dei clienti. La pratica di separare i dati per evitare la ridondanza è chiamata normalizzazione. I progettisti di database progressivi si assicurano che le tabelle si normalizzino durante il processo di progettazione.
I database relazionali sono transazionali: garantiscono che lo stato dell'intero sistema sia coerente in ogni momento. La maggior parte di essi offre facili opzioni di esportazione e importazione, rendendo il backup e il ripristino davvero semplici. Queste esportazioni possono avvenire anche mentre il database è in funzione, rendendo facile il ripristino in caso di guasto. Quelli moderni, basati sul cloud, possono fare un mirroring continuo, ovvero duplicare i dati su più dischi fissi, evitando la loro perdita in caso di ripristino.
Oltre ai benefici, i database relazionali presentano anche alcuni svantaggi. Il principale è il costo dell'impostazione e del mantenimento del sistema. Per impostare un database relazionale, occorre acquistare un software specifico ed è necessario contare su un programmatore per creare un database relazionale usando il linguaggio SQL e un amministratore dedicato a mantenere il database una volta costruito. Indipendentemente dai dati utilizzati, occorre importarli da altri, come file di testo o fogli di calcolo Excel. Non importa la dimensione della vostra azienda, se memorizzate informazioni legalmente confidenziali o protette nel vostro database come informazioni sanitarie, numeri di previdenza sociale o numeri di carte di credito, dovrete anche proteggere i dati da accessi non autorizzati per soddisfare gli standard normativi.
L'abbondanza di informazioni e la loro progressiva complessità rappresentano un altro svantaggio per i database relazionali. Essi sono fatti per organizzare i dati secondo caratteristiche comuni. Immagini complesse, numeri, disegni e prodotti multimediali sfidano una facile categorizzazione, portando la strada a un nuovo tipo di database chiamato sistemi di gestione di database relazionali a oggetti (ORDBMS). Essi sono progettati per gestire le applicazioni più complesse e hanno la capacità di essere scalabili.
Alcuni database relazionali presentano limiti sulla lunghezza dei campi. Quando viene progettato, occorre specificare la quantità di dati da poter inserire in un campo. Alcuni nomi o query di ricerca sono più corti del reale, e questo può portare alla loro perdita.
Infine, quelli più complessi possono portare a diventare "isole di informazioni" dove le informazioni non possono essere condivise facilmente da un grande sistema all'altro. Fare in modo che questi database "parlino" tra loro può rivelarsi un'impresa complessa e costosa.
Le performance peggiori rispetto ai database NoSQL rappresentano un altro punto da considerare. Il modello di database relazionale ha requisiti molto rigidi in termini di coerenza dei dati che nelle transazioni vanno a discapito della velocità di scrittura. I limiti dei classici sistemi relazionali sono messi in evidenza soprattutto nell'amministrare grandi quantità di dati nel contesto di big data analytics e dall'archiviazione di tipi astratti, dove si distinguono invece sistemi specializzati come i database a oggetto o i concetti sviluppati nell'ambito del movimento NoSQL. Va detto, però, che il modello di database relazionale è chiaro, matematicamente valido e ha alle spalle più di 40 anni di utilizzo pratico.
Come Progettare un Database Relazionale
Un database ben progettato permette di fare due cose: eliminare la ridondanza dei dati e assicurarne l'integrità e l'accuratezza. I database sono di solito personalizzati per soddisfare una particolare applicazione. Non ci sono due applicazioni personalizzate uguali, e quindi non ci sono due database uguali. Tutto questo vale anche per i database relazionali la cui progettazione deve tenere conto di quattro importanti passi:
- Definire lo scopo del database: Questo implica la necessità di raccogliere i requisiti e definire l'obiettivo del database.
- Raccogliere e organizzare i dati: Creare tabelle e specificare le chiavi primarie. Una volta deciso lo scopo del database, raccogliete i dati che devono essere memorizzati nel database.
- Creare relazioni tra le tabelle: La potenza del database relazionale sta, appunto, nelle relazioni che possono essere definite tra le tabelle. L'aspetto cruciale nella progettazione è, quindi, identificare le relazioni tra le tabelle.
- Raffinare e normalizzare il progetto: Ad esempio, aggiungere più colonne, creare una nuova tabella per i dati opzionali usando, per esempio, una relazione uno-a-uno (nella quale un record in una tabella è associato a un unico record in un'altra tabella), dividere una tabella grande in due tabelle più piccole.
Altri Modelli di Database
Il database relazionale è uno dei quattro tipi comuni di sistemi che si può usare per gestire i dati aziendali. Gli altri tre sono: database gerarchici, database reticolare, database orientati agli oggetti e NoSQL.
- Database Gerarchico: Questo modello di database assomiglia a una struttura ad albero, simile a un'architettura di cartelle nel sistema informatico. Le relazioni tra i record sono predefinite in un rapporto "uno a uno". Inoltre, il modello gerarchico consente di rappresentare informazioni usando la relazione tra segmenti "padre" e segmenti "figli": ogni padre può avere molti figli, ma ogni figlio può avere un solo padre. Tale modello presenta due svantaggi: a causa della struttura ad albero dello schema logico, per ottenere relazioni di tipo molti-a-molti è necessario duplicare i dati. Per accedere ai dati occorre attraversare tutto l'albero partendo dalla radice fino al nodo interessato.
- Database Reticolare: Anche il database reticolare ha una struttura gerarchica. Tuttavia, invece di usare una gerarchia ad albero con un solo genitore, questo modello supporta le relazioni molti a molti, poiché le tabelle figlio possono avere più di un genitore. A differenza di quello relazionale che si basa su gruppi di record, ne considera uno alla volta.
- Database Orientato agli Oggetti: Il modello di database orientato agli oggetti collega tra loro pacchetti che appartengono allo stesso gruppo: un set di dati viene associato con tutti i suoi attributi a un unico oggetto. In tal modo, tutte le informazioni sono direttamente disponibili. Così, invece di essere distribuiti in diverse tabelle, i dati sono disponibili insieme.
- Database NoSQL (Non Relazionali): I NoSQL o database non relazionali, sono un'alternativa popolare ai database relazionali. Essi assumono una varietà di forme e permettono di memorizzare e manipolare grandi quantità di dati non strutturati e semi-strutturati. Sebbene esistano dalla fine degli anni Sessanta, il nome "NoSQL" è stato coniato solo all'inizio del Duemila, innescato dalle esigenze delle aziende del Web 2.0.

Oracle Database: Caratteristiche e Versioni
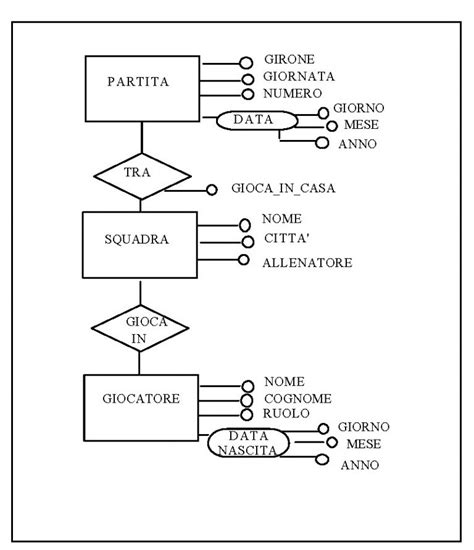
Oracle Database è uno tra i più famosi software di database management system sviluppato da Oracle Corporation. La società informatica che lo produce, la Oracle Corporation, è una delle più grandi del mondo, fondata nel 1977 da Lawrence J. Ellison (attuale amministratore delegato, Chief Technology Officer ed importante azionista), Bob Miner e Ed Oates, con sede centrale in California. Una base di dati Oracle comprende istanze e dati memorizzati. Un'istanza è costituita da un insieme (set) di processi di sistema e strutture di memoria che interagiscono con i dati memorizzati. Un compito importante è svolto dalla System Global Area (SGA), una regione di memoria condivisa che contiene dati ed informazioni per il controllo di un'istanza Oracle. Oracle memorizza i dati sia logicamente, sotto forma di tablespace, sia fisicamente, sotto forma di file (datafile). Un tablespace, formato da uno o più datafile, contiene vari tipi di segment; ogni segment a sua volta si suddivide in uno o più extent. Ogni extent comprende gruppi contigui di blocchi di dati (data block), questi ultimi sono la più piccola informazione memorizzabile da Oracle. A livello fisico, i file comprendono almeno due o più extent. Oracle tiene traccia dei dati memorizzati tramite l'aiuto di informazioni presenti nelle tabelle di sistema. Esse contengono il dizionario dei dati e se presenti indici e cluster.
La funzionalità RAC (Real Application Clusters) consente a più computer di eseguire contemporaneamente il software Oracle RDBMS accedendo a un singolo database, garantendo così il clustering. Tra le varie potenzialità possiamo memorizzare ed eseguire stored procedure e funzioni. Grazie al PL/SQL, un'estensione procedurale del linguaggio SQL, sviluppato da Oracle, e a Java possiamo scrivere funzioni, procedure, trigger e package. Oracle è un RDBMS che se configurato e gestito in maniera appropriata, garantisce una sicurezza dei dati molto elevata. È possibile attivare a questo proposito la modalità detta ARCHIVING (o ARCHIVELOG MODE). Essa consiste nel registrare tutte le transazioni che avvengono nel DB anche in file di sistema operativo che dovranno essere utilizzati in caso di DB RECOVERY dovuta a crash totale o parziale del sistema. In questa modalità è possibile sfruttare l'HOT BACKUP ossia il salvataggio dei dati a sistema acceso senza effettuare fermi. Le modalità per il backup a caldo (hot backup) sono diverse. Quella standard Oracle è denominata RMAN ossia Recovery Manager.
Strumenti Importanti per Oracle Database
Per lo sviluppo e l'estensione dei database, Oracle mette a disposizione diversi strumenti sia per gli sviluppatori che per gli amministratori:
- SQLPlus: Disponibile per tutti i sistemi per computer che usano i software per client e server di Oracle. Come strumento a riga di comando per la gestione del database consente di inviare comandi, consultare i dati, cancellare e apportare modifiche ai file del database. La conoscenza di SQL è indispensabile per l'uso di SQLPlus.
- Oracle SQL Developer: Un programma Java gratuito con interfaccia utente grafica che crea ed elabora i progetti di database, gestisce gli script e gli statement SQL, esegue analisi del database, genera procedure PL/SQL e consente il debugging.
- Oracle Data Modeler: Uno strumento gratuito che si rivolge principalmente ai designer di database. Con Modeler si possono disegnare modelli logici di database o modelli di entity relationship. I punti di forza del tool sono il suo utilizzo intuitivo (tramite drag&drop), la riproduzione di strutture di database complesse, così come l'esportazione delle strutture di database in Oracle SQL Developer.
- Oracle Enterprise Manager Database Control: Uno strumento di amministrazione per i database Oracle basato sul web che offre un'interfaccia utente grafica.
- Oracle Enterprise Manager Grid Control: Uno strumento di amministrazione flessibile per gli ambienti Oracle basato sul web e che lavora con un'interfaccia utente grafica. Può essere usato per più database, per interi cluster o per sistemi standby.
- Oracle JDeveloper: Uno strumento per sviluppatori che lavorano con Oracle che serve ad aiutare il loro ambiente di sviluppo integrato nello sviluppo di applicazioni di database con Oracle e Java.
Versioni e Settori di Utilizzo di Oracle Database
Attualmente i prodotti Oracle Database possono essere suddivisi in tre versioni Oracle essenziali, ciascuna adatta per diversi campi di applicazione in base alla dimensione dell'azienda:
- Express Edition (XE): Oracle Express Edition è un Oracle Database, adatto a ogni client e che mette a disposizione un database gratuito (per esempio per piccole applicazioni o corsi di formazione). Express Edition supporta PHP, Java, XML e .NET. Trattandosi di una versione gratuita lo spazio di archiviazione è limitato a 4 GB e la RAM a 1 GB con una sola CPU.
- Standard Edition: Oracle Standard Edition è scelta principalmente dalle imprese di medie dimensioni. I vantaggi della Standard Edition sono l'installazione e la configurazione intuitive, le funzionalità di gestione automatizzate, l'amministrazione efficiente e chiara di grandi record di dati, così come un'elevata compatibilità con tutti i tipi di dati e applicazioni più comuni.
- Enterprise Edition: Enterprise Edition di Oracle è la versione di lusso di Oracle Database e fa parte dell'élite degli RDBMS. Poiché la Enterprise Edition non ha praticamente limiti per quanto riguarda l'archiviazione, le estensioni e la gestione delle quantità di dati, è prevalentemente adatta alle imprese di grandi dimensioni che lavorano con enormi quantità di dati. Ulteriori vantaggi sono le affidabili funzionalità di protezione e sicurezza contro la perdita di dati, la mancanza di corrente elettrica (blackout) e i malfunzionamenti lato software.
I vantaggi e gli svantaggi di Oracle dipendono in prima linea dalle aspettative e dalle esigenze dell'utente così come dalle capacità finanziarie, dalle competenze tecniche e dalle conoscenze dei programmatori coinvolti. Un grande vantaggio di Oracle Database è il modello opzionale Database as a Service che permette l'archiviazione e l'amministrazione di database relazionali nell'infrastruttura cloud di Oracle. Ciò rende possibile lo sfruttamento massimo della CPU, dell'hardware e dello spazio di archiviazione così come anche delle operazioni di gestione del database. I più elevati criteri di sicurezza garantiscono la migliore protezione possibile contro la perdita dei dati, gli attacchi cibernetici e le falle di sicurezza.
Vantaggi:
- L'elevata compatibilità con tutte le applicazioni e le piattaforme.
- L'essere supportato da tutti i principali produttori hardware e software.
- Diverse versioni, da quella gratuita a quella Enterprise.
- La diffusione nel settore imprenditoriale legato all'IT.
- L'utilizzo opzionale dei database cloud di Oracle per lo sfruttamento ottimizzato e l'automazione della gestione dei database.
- Il sistema più popolare di gestione di database relazionale.
- Una grande comunità di sviluppatori e l'eccezionale supporto offerto da Oracle.
- Funzionalità affidabili di sicurezza e protezione dati (per esempio autenticazione e autorizzazione rigorose degli accessi, crittografia dei dati e delle reti).
Svantaggi:
- Le conoscenze di SQL e l'esperienza nell'amministrazione di database sono un prerequisito per l'utilizzo della versione on premise di Oracle.
- Le licenze Oracle hanno un prezzo molto elevato (la versione Standard costa circa 17.000 euro lordi e la versione Enterprise circa 40.000 euro lordi).
- Requisiti hardware elevati per la versione locale on premise.
Database: Panoramica Completa (o quasi...)
Alternative ai Database Oracle
Se Oracle Database va oltre le vostre possibilità, potete comunque scegliere tra numerosi sistemi di gestione di database alternativi. Qui di seguito trovate le alternative a Oracle Database:
- SAP HANA
- IBM Db2
- Amazon Relational Database Service (RDS)
- Amazon Aurora
- Microsoft SQL
- MySQL
- SQLite
- Azure SQL Database
In aggiunta a queste ci sono anche sistemi di gestione di database open source e gratuiti:
- MariaDB
- NoSQL (come InfluxDB, CouchDB, MongoDB)
- PostgreSQL
Il concetto di relatività nel contesto delle basi di dati si riferisce al modo in cui i dati vengono organizzati e gestiti. L'idea principale alla base delle basi di dati relazionali è l'utilizzo di tabelle per memorizzare i dati e definire le relazioni tra di esse.
Differenza rispetto ai Database Non Relazionali
I database relazionali memorizzano i dati in tabelle con uno schema fisso e supportano SQL per le query. Sono adatti per dati strutturati con relazioni chiare tra di essi.
I database non relazionali (NoSQL) possono utilizzare diversi modelli di archiviazione dei dati (documenti, grafi, chiave-valore) e non richiedono uno schema fisso. Sono particolarmente adatti per dati non strutturati e grandi volumi di dati che richiedono elevata scalabilità e flessibilità.
Applicazione dei Database Relazionali
I database relazionali sono più indicati quando è necessario archiviare dati chiaramente strutturati, in cui ogni informazione è collegata ad un'altra. Sono ideali in contesti in cui è fondamentale l'integrità dei dati e deve essere garantita l'accuratezza.
Inoltre, i database relazionali diventano fondamentali quando è necessario eseguire query complesse e gestire transazioni, garantendo l'affidabilità delle operazioni e il rispetto di tutte le relazioni tra i dati.
tags: #dbms #relazionali #oracle