Un database relazionale è una raccolta di informazioni strutturate che organizza i dati in relazioni predefinite. In questo tipo di database, i dati vengono archiviati in una o più tabelle, composte da colonne (attributi) e righe (record o tuple). Questa organizzazione semplifica notevolmente la visualizzazione e la comprensione di come le diverse strutture di dati sono correlate tra loro. Le relazioni rappresentano una connessione logica tra le tabelle, stabilita sulla base dell'interazione tra i dati che contengono.
Definizione e Modello Relazionale
Un database relazionale (RDB) è, in sostanza, un modo per strutturare le informazioni in tabelle, righe e colonne. La sua caratteristica distintiva è la capacità di stabilire collegamenti (o relazioni) tra le informazioni unendo le tabelle, il che semplifica la comprensione e l'acquisizione di insight sulla relazione tra i vari punti dati.
Il modello di database relazionale, sviluppato da Edgar F. Codd di IBM negli anni '70, ha rivoluzionato la gestione dei dati. Codd propose di collegare qualsiasi tabella a un'altra tabella utilizzando un attributo comune. Anziché affidarsi a strutture gerarchiche per organizzare i dati, il modello relazionale ha introdotto un approccio in cui i dati sono accessibili, archiviati e correlati all'interno di tabelle senza la necessità di riorganizzare le tabelle stesse.
Si può pensare a un database relazionale come a una raccolta di fogli di lavoro interconnessi che aiutano le organizzazioni a organizzare, gestire e correlare i dati. In questo modello, ogni "foglio di lavoro" è una tabella che archivia le informazioni. Gli attributi (colonne) specificano un tipo di dati, mentre ogni record (o riga) contiene il valore per quel tipo di dati specifico.
Un elemento cruciale di ogni tabella in un database relazionale è la chiave primaria. Questa è un identificatore univoco per ogni riga, garantendo che nessun altro record possa avere lo stesso valore. Per creare connessioni tra tabelle diverse, si utilizza una chiave esterna, che funge da riferimento a una chiave primaria di un'altra tabella esistente.
Esempio Pratico: Cliente e Ordine
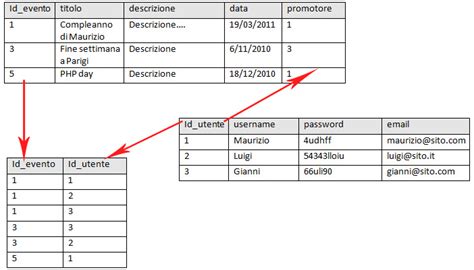
Consideriamo due tabelle: Cliente e Ordine.
- Tabella Cliente:
ID cliente(chiave primaria)Nome clienteIndirizzo di fatturazioneIndirizzo di spedizione
In questa tabella, ID cliente identifica univocamente ogni cliente nel database.
- Tabella Ordine:
ID ordine(chiave primaria)ID cliente(chiave esterna)Data ordineData di spedizioneStato dell'ordine
Qui, ID ordine è la chiave primaria per identificare un ordine specifico. È possibile collegare un cliente a un ordine utilizzando l'ID cliente come chiave esterna, che fa riferimento all'ID cliente nella tabella Cliente. Le due tabelle sono ora correlate tramite l'ID cliente condiviso. Questo consente di eseguire query su entrambe le tabelle per generare report dettagliati. Ad esempio, un responsabile vendite potrebbe creare un report su tutti i clienti che hanno effettuato un acquisto in una data specifica o identificare gli ordini la cui consegna è stata ritardata.
I database relazionali eccellono nel rappresentare relazioni complesse tra i dati, permettendo di fare riferimento a dati in più tabelle, a condizione che questi dati aderiscano allo schema relazionale predefinito. Poiché i dati sono organizzati come relazioni predefinite, è possibile interrogarli in modo dichiarativo. Una query dichiarativa specifica cosa si desidera estrarre dal sistema, senza dover descrivere come il sistema debba calcolare il risultato. Questo è un principio fondamentale dei sistemi relazionali, che li distingue da altri tipi di sistemi.
Sistemi di Gestione di Database Relazionali (RDBMS)
Un sistema di gestione di database relazionali (RDBMS) è il software utilizzato per creare, aggiornare e gestire i database relazionali. Tra gli RDBMS più noti figurano MySQL, PostgreSQL, MariaDB, Microsoft SQL Server e Oracle Database.
Negli ultimi anni, i database relazionali basati su cloud, come Cloud SQL, Cloud Spanner e AlloyDB per PostgreSQL di Google Cloud, hanno guadagnato popolarità. Questi servizi offrono gestione automatizzata per attività come manutenzione, applicazione di patch, gestione della capacità, provisioning e supporto infrastrutturale, riducendo significativamente i costi operativi e semplificando lo sviluppo di applicazioni trasformative.
Introduzione ai database relazionali e nozioni di base su SQL
Vantaggi Chiave dei Database Relazionali
Il modello di database relazionale offre un modo intuitivo per rappresentare i dati e consente un facile accesso ai punti dati correlati. Di conseguenza, i database relazionali sono ampiamente utilizzati dalle organizzazioni che gestiscono grandi quantità di dati strutturati, dal monitoraggio dell'inventario all'elaborazione dei dati transazionali e al logging delle applicazioni.
I vantaggi principali includono:
- Flessibilità: È relativamente semplice aggiungere, aggiornare o eliminare tabelle, relazioni e apportare modifiche ai dati senza alterare la struttura complessiva del database o interferire con le applicazioni esistenti.
- Conformità ACID: I database relazionali supportano le proprietà ACID (Atomicità, Coerenza, Isolamento, Durabilità) per garantire la validità dei dati indipendentemente da errori, guasti o altri potenziali incidenti.
- Atomicità: Garantisce che tutte le operazioni all'interno di una transazione vengano completate con successo o che nessuna venga eseguita. Ad esempio, un trasferimento di denaro tra due conti bancari deve completare sia la detrazione che l'accredito, altrimenti l'intera operazione viene annullata.
- Coerenza: Assicura che una transazione porti il database da uno stato valido a un altro stato valido, mantenendo l'integrità dei dati.
- Isolamento: Garantisce che le transazioni concorrenti non interferiscano tra loro, facendo apparire ogni transazione come se venisse eseguita in isolamento.
- Durabilità: Una volta che una transazione è stata confermata (committata), le sue modifiche sono permanenti e sopravvivono a eventuali guasti del sistema.
- Facilità d'uso: L'utilizzo di SQL (Structured Query Language), un linguaggio potente e standardizzato, semplifica l'esecuzione di query complesse, rendendo i database relazionali accessibili anche a utenti non esperti.
- Collaborazione: Più utenti possono operare e accedere ai dati contemporaneamente. I meccanismi di blocco integrati impediscono l'accesso simultaneo ai dati in fase di aggiornamento, garantendo l'integrità.
- Sicurezza integrata: La sicurezza basata sui ruoli limita l'accesso ai dati a utenti specifici, garantendo un controllo granulare sulle autorizzazioni.
- Normalizzazione del database: I database relazionali impiegano una tecnica di progettazione chiamata normalizzazione che riduce la ridondanza dei dati e migliora l'integrità dei dati, eliminando duplicazioni non necessarie e garantendo che ogni informazione sia memorizzata in un unico posto.
- Indipendenza dei dati: Il modello relazionale separa la struttura logica dei dati (tabelle, viste, indici) dalle strutture di storage fisico. Questa indipendenza logica e fisica consente agli amministratori di database di gestire lo storage senza compromettere l'accesso ai dati e viceversa.
Confronto con i Database Non Relazionali (NoSQL)
La differenza fondamentale tra database relazionali e database non relazionali (spesso indicati come database NoSQL) risiede nel modo in cui archiviano e organizzano i dati. Mentre i database relazionali utilizzano un formato tabellare basato su regole rigide, i database NoSQL sono più flessibili.
I database non relazionali archiviano i dati come singoli file scollegati e sono ideali per tipi di dati complessi e non strutturati, come documenti, file multimediali o dati in tempo reale. Il loro modello di dati flessibile li rende adatti per applicazioni che gestiscono dati che cambiano frequentemente o che coinvolgono diversi tipi di dati.

A differenza dei database relazionali, che tendono a scalare verticalmente (aumentando le risorse di una singola macchina), i database NoSQL sono spesso progettati per scalare orizzontalmente (aggiungendo più macchine a un cluster), rendendoli adatti per applicazioni su larga scala e carichi di lavoro distribuiti.
Evoluzione e Futuro dei Database Relazionali
Nonostante l'emergere di nuove tecnologie, i database relazionali continuano a essere il fondamento della gestione dei dati per molte aziende. La loro longevità è attribuita alla loro robustezza, alla coerenza dei dati e alla maturità dell'ecosistema SQL.
Negli ultimi anni, la tecnologia dei database si è evoluta per affrontare le sfide di complessità e gestione. I database self-driving (o autonomi) rappresentano l'ultima frontiera, combinando i punti di forza del modello relazionale con l'intelligenza artificiale (AI), il machine learning e l'automazione. Questi database utilizzano queste tecnologie per monitorare e ottimizzare autonomamente le performance delle query e le attività di gestione, liberando gli sviluppatori da compiti ripetitivi e permettendo loro di concentrarsi sull'innovazione.
I database relazionali, grazie alla loro struttura organizzata, alla garanzia di integrità dei dati tramite le proprietà ACID e alla potenza del linguaggio SQL, rimangono una scelta privilegiata per una vasta gamma di applicazioni, dalle piccole imprese alle grandi corporazioni globali. La loro capacità di gestire dati strutturati con alta coerenza e affidabilità li rende insostituibili in molti scenari critici.
tags: #dbms #e #database #relazionali