I database sono il pilastro su cui poggia l'architettura delle applicazioni moderne, mantenendo la memoria della nostra storia digitale. La loro evoluzione è stata guidata dall'esplosione dei dati da trattare, derivanti da social media, Internet of Things (IoT), mobile e interazioni con i clienti. Questa crescita esponenziale impone una scelta oculata del tipo di database più adatto per applicazione, prestazioni e costi. L'appassionante evoluzione nella comunicazione tra persone, aziende e oggetti genera continuamente nuovi tipi di dati, li aggrega in forme sempre più vantaggiose e rende disponibili servizi sempre più utili. Per questo motivo, anche il C-Level o il dirigente di spesa devono avere un'infarinatura della tecnologia disponibile.
Il panorama dei database si divide principalmente in due grandi categorie: relazionale e non relazionale. Un altro modo di indicare questa caratteristica è riferirsi al linguaggio di ricerca: nei database relazionali è l'SQL (Structured Query Language), mentre nei "non relazionali" si parla di No-SQL (Not Only SQL). Esistono svariate decine di database o sistemi analoghi, più o meno completi e ricchi di funzionalità, ma è necessario concentrarsi sui principali per una scelta informata.
Database Relazionali: La Stabilità del Modello Tabellare
I database relazionali, comunemente indicati come SQL (Structured Data Language), archiviano le informazioni in tabelle, righe e colonne. Sono ideali per dati strutturati che subiscono raramente modifiche. La loro caratteristica distintiva è l'adozione di uno schema fisso, basato su tabelle, per definire entità e relazioni. Ogni tabella rappresenta un'entità (ad esempio, un cliente, un prodotto, un ordine), le sue colonne sono gli attributi (come nome, prezzo, quantità) e le righe sono i singoli record, ossia le istanze specifiche di quell'entità. Le tabelle possono essere collegate tra loro tramite relazioni, stabilendo come i dati di una tabella si riferiscono a quelli di un'altra.
La principale caratteristica dei database relazionali è l'offerta di operazioni ACID (Atomic, Consistent, Isolated, Durable), che garantiscono:
- Atomic: Tutte le operazioni in una transazione o hanno successo, o vengono annullate.
- Consistent: Al completamento di una transazione, il database è integro.
- Isolated: Le transazioni non si scontrano tra loro e le concorrenze di accesso ai dati vengono gestite in modo da garantire l'integrità del database.
- Durable: I risultati delle transazioni sono permanenti.
Con queste proprietà, i database relazionali sono l'ideale per applicazioni finanziarie, bancarie, di e-commerce e ovunque sia indispensabile e critico mantenere la perfetta integrità dei dati.
SQL (Structured Query Language) è il linguaggio standard utilizzato per interrogare e manipolare i dati nei database relazionali. È un metodo collaudato da decenni per accedere ai dati, e la maggior parte degli sviluppatori e degli amministratori di database lo conosce.
Principali Database Relazionali
- Microsoft SQL Server: Un database relazionale proprietario di tipo tradizionale, disponibile in molte versioni, ciascuna rivolta a specifici carichi di lavoro. OLAP e data mining sono disponibili tramite gli Analysis Services. Dal mainframe all'open source, è disponibile anche a uso libero con la versione Express-C.
- Oracle: Nato con i database, Oracle è ora un vendor di ICT a 360 gradi, che si propone non solo nel software (DBMS e applicazioni) ma anche nell'hardware e nei servizi cloud. È uno storico database relazionale, oggi aperto anche all'approccio a oggetti e a strutture non relazionali quali JSON ed XML. Tra le piattaforme di riferimento c'è anche il mainframe.
- MySQL: Uno dei database relazionali più diffusi, rappresenta un sistema di gestione di database open source ampiamente utilizzato per le sue prestazioni, l'affidabilità e la semplicità d'uso. La sua lunga storia parte sotto il nome di Ingres nel 1977, successivamente riscritto come PostgreSQL.
- IBM DB2: Lo storico database relazionale di IBM, oggi aperto anche all'approccio a oggetti e a strutture non relazionali quali JSON ed XML. Esiste in varie edizioni, tra cui la Express-C è di uso libero.
- SAP HANA: La High-performance ANalytic Appliance di SAP, HANA, è più di un DBMS proprietario. Si tratta di una OLAP Data Platform, che integra OLTP, OLAP e dati più innovativi, oltre a una completa suite di real-time analytics e un application server. La parte strettamente legata al database può essere descritta come un DBMS relazionale in-memory e basato su colonne.
- EDB Postgres (PostgreSQL): PostgreSQL, o più semplicemente Postgres, è un database relazionale avanzato e potente, sviluppato in open source da una community che partecipa con un elevato livello di supporto. Supporta molte funzionalità come transazioni, viste materializzate, funzioni definite dall'utente e tipi di dati personalizzati. È considerato più efficiente di MySQL, in particolare per carichi di lavoro con query complesse e scritture pesanti.
- Kinetica: Una piattaforma che combina la potenza dei database relazionali e non relazionali, offrendo capacità di analisi in tempo reale su grandi volumi di dati.
Cosa significa: database, linguaggio SQL e query [SQL TUTORIAL]
Database Non Relazionali (NoSQL): Flessibilità e Scalabilità
I database non relazionali, spesso indicati come NoSQL (Not Only SQL), rappresentano una categoria di sistemi di gestione di database progettati per gestire dati con una struttura più flessibile e scalabile rispetto ai tradizionali database relazionali. Questi database sono diventati sempre più popolari grazie alla loro capacità di gestire grandi volumi di dati, dati non strutturati e semi-strutturati, e di adattarsi facilmente a cambiamenti nei requisiti dell'applicazione.
A differenza del modello classico relazionale, i database non relazionali offrono flessibilità nel trattare dati dinamici e non strutturati. Lo schema di dati è flessibile: non c'è uno schema rigido, e per questo possono essere aggiunti nuovi campi o modificati quelli esistenti senza impatti sistemici significativi. Questa è una differenza cruciale rispetto ai database relazionali, dove ogni modifica alla struttura del database può richiedere modifiche allo schema e impattare sulle prestazioni.
Le caratteristiche principali dei database NoSQL includono:
- Supporto per dati non strutturati e semi-strutturati: Molte applicazioni moderne devono gestire dati eterogenei (documenti, file multimediali, JSON).
- Schema di dati flessibile: Permette di aggiungere o modificare campi senza impatti sistemici.
- Altissime prestazioni: Ottimizzati per operazioni ad alte prestazioni, gestendo migliaia di richieste al secondo o anche di più, soprattutto per query complesse su grandi volumi di dati dove le performance dei database relazionali possono degradare.
- Esigenza di scalabilità orizzontale: A differenza dei database relazionali che tendono a scalare verticalmente (aumentando la potenza del singolo server), i database NoSQL scalano orizzontalmente, ovvero aggiungendo nodi e macchine, rendendoli più efficienti ed economici per l'aumento esponenziale dei volumi di dati.
I database NoSQL non memorizzano i dati esclusivamente in righe e tabelle, ma utilizzano diversi modelli:
Principali Tipi di Database NoSQL
Database a Documenti: Memorizzano i dati sotto forma di documenti, spesso in formato JSON, BSON o XML. Ogni documento è un'unità autonoma, può avere una struttura diversa e può essere modificato senza impattare sulla struttura del database. Offrono potenti meccanismi di indicizzazione e di query.
- MongoDB: Un database documentale NoSQL, perfetto come database generico e particolarmente utile per la mancanza di uno schema. La sua architettura senza schema consente di memorizzare dati molto diversi tra loro. I documenti sono organizzati all'interno di collezioni, il corrispettivo delle tabelle nei database relazionali.

Database a Grafo: Progettati per gestire dati altamente connessi, come reti sociali, reti di trasporto o mappe concettuali. Rappresentano le entità come nodi e le relazioni come archi.
- Neo4j: Un database a grafi particolarmente efficace nella memorizzazione delle relazioni tra data point. È un modello perfetto per rappresentare reti complesse di connessioni tra le entità; l’applicazione per eccellenza sono i social network.
Database Wide-Column: Organizzati in colonne flessibili. A differenza dei database relazionali, dove lo schema è rigido e uniforme per tutte le righe, in quelli wide-column le colonne possono variare, a livello di nome e anche di formato, da riga a riga all’interno della stessa tabella.
- Apache Cassandra: Un esempio di database wide-column, efficiente per gestire dati in costante evoluzione e per eseguire operazioni di lettura e scrittura su larga scala.
Database Key-Value: Memorizzano i dati come coppie chiave-valore, offrendo un accesso estremamente veloce e semplificato alle informazioni. Sono ideali per applicazioni di caching e per la memorizzazione delle informazioni sulla sessione utente (es. carrelli dell'e-commerce).
- Redis: Un database key-value NoSQL particolarmente utile nel settore dei videogiochi, dove sono essenziali operazioni ad alta velocità. Offre latenza minima ed elevatissime performance, ideale per creare chat e applicazioni di feeding di dati.
Database Multimodello: Possono operare su diversi modelli di dati contemporaneamente.
- OrientDB: Un database NoSQL a oggetti (OODBMS) con un approccio multimodello o ibrido, in quanto può operare su Graph, Document, Key-Value, GeoSpaziale e Reactive.
Considerazioni Tecnologiche: Teorema CAP e Coerenza dei Dati
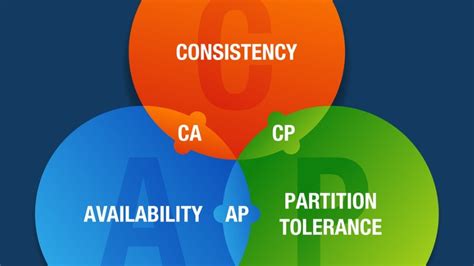
La scelta tra database relazionale e non relazionale non è sempre netta e dipende dalle esigenze specifiche del progetto. Un fattore cruciale da considerare, soprattutto per i sistemi distribuiti, è il Teorema CAP. Questo teorema afferma che un sistema di dati distribuito non può contemporaneamente garantire tre proprietà:
- Coerenza (Consistency): Ogni nodo del cluster risponde con i dati più recenti, anche se il sistema deve attendere l'aggiornamento di tutte le repliche.
- Disponibilità (Availability): Ogni richiesta ricevuta da un nodo non in errore nel sistema deve generare una risposta.
- Tolleranza di Partizione (Partition Tolerance): Il sistema continua a funzionare anche in presenza di interruzioni nella comunicazione tra i nodi.
In pratica, un sistema distribuito può garantire al massimo due di queste tre proprietà. Molti database relazionali offrono coerenza e disponibilità, ma hanno limitazioni nella tolleranza di partizione. Al contrario, i database NoSQL tendono a privilegiare disponibilità e tolleranza di partizione, sacrificando talvolta la coerenza assoluta a favore di una "coerenza finale".
La coerenza dei dati si riferisce all'integrità dei dati. La maggior parte dei database distribuiti consente agli sviluppatori di scegliere tra due modelli di coerenza:
- Coerenza Assoluta (Strong Consistency): Garantisce che una query restituisca sempre i dati più recenti, anche se ciò comporta una latenza in attesa della replica di un aggiornamento in tutte le copie del database. Questo è lo standard di riferimento per la programmabilità dei dati e offre garanzie ACID.
- Coerenza Finale (Eventual Consistency): Un database configurato per coerenza finale restituirà immediatamente i dati, anche se non sono la copia più recente. Questo modello privilegia la disponibilità e la velocità di risposta.
Queste opzioni consentono di effettuare scelte precise e compromessi granulari per coerenza, disponibilità e prestazioni dei dati.
Scelta del Database: Un Approccio Ibrido e Orientato al Business
Partire con il piede giusto è sempre più necessario in un mondo attraversato da un gigantismo dei dati. La scelta di un sistema di gestione dei dati può anche comprendere valutazioni di tipo economico, ma la componente tecnologica e la traiettoria dei DBMS (Database Management Systems) vanno messe in primo piano per garantire robustezza e durata del progetto.
Per progetti business-critical e complessi, la scelta del database è sempre un momento difficile. Virare verso una soluzione in particolare o verso un'alternativa richiede una comprensione completa dello use case e dei requisiti specifici necessari per essere aderenti al piano operativo e funzionale.
L'approccio che molte aziende esperte adottano è quello di non affidarsi a un unico database, ma di sfruttare il meglio di tutti quelli reputati necessari per garantire efficienza e performance ai minimi costi per il cliente. Questo approccio ibrido consente di costruire architetture consistenti, ad alta affidabilità e disponibilità, gestibili, manutenibili ai costi più bassi possibili, scalabili e modulari, perfettamente aderenti alle esigenze specifiche.
Seguendo un approccio orientato ai nuovi paradigmi del Site Reliability Engineering (SRE), è possibile concentrarsi sul proprio business potendo effettuare il deploy di nuovi prodotti e funzionalità in maniera sicura, garantita e con i minimi costi. Scegliere un'unica soluzione invece limita e non permette di ottimizzare performance e costi, assumendosi inoltre il rischio di un sort of lock-in per un prodotto che potrebbe rappresentare un problema per l'evoluzione delle applicazioni.
Esempi di Soluzioni Cloud per Database
Le principali piattaforme cloud offrono una vasta gamma di servizi gestiti sia per database relazionali che non relazionali, semplificando notevolmente il provisioning, la gestione, la scalabilità e la sicurezza.
Per Database Relazionali (SQL):
- Microsoft Azure: Offre Azure SQL Database (un DBaaS completamente gestito basato sul motore di Microsoft SQL Server), Azure Database for MySQL, Azure Database for MariaDB e Azure Database for PostgreSQL. Quest'ultimo, in particolare, con l'opzione Hyperscale (Citus), permette di scalare orizzontalmente un singolo database tra centinaia di nodi.
- Google Cloud: Propone Cloud SQL (un servizio gestito ideale per CMS, ERP e e-commerce), Cloud Spanner (una piattaforma globale enterprise con disponibilità del 99,999%) e soluzioni Bare Metal per migrare database Oracle.
- Amazon Web Services (AWS): Offre Amazon RDS (Relational Database Service) che supporta diversi motori di database come MySQL, PostgreSQL, MariaDB, Oracle e SQL Server, oltre ad Amazon Aurora, un database relazionale compatibile con MySQL e PostgreSQL, ottimizzato per il cloud.
Per Database Non Relazionali (NoSQL):
- Microsoft Azure: Presenta Azure Cosmos DB, un servizio di database NoSQL completamente gestito e distribuito a livello globale, che supporta diversi modelli di dati (documento, grafo, key-value, wide-column) tramite API compatibili con MongoDB, Cassandra, Gremlin e altre. Offre anche Azure Cache for Redis per soluzioni di caching.
- Google Cloud: Dispone di Firestore (una piattaforma serverless, scalabile automaticamente, ideale per applicazioni backend e real-time) e Cloud Bigtable (un database NoSQL ad alte prestazioni per grandi volumi di dati non strutturati, ideale per IoT e monitoraggio). Memorystore offre servizi di caching basati su Redis e Memcached.
- Amazon Web Services (AWS): Offre Amazon DynamoDB (un database key-value e a documenti completamente gestito, scalabile e ad alte prestazioni), Amazon DocumentDB (compatibile con MongoDB), Amazon Keyspaces (compatibile con Apache Cassandra) e Amazon Neptune (un servizio di database a grafo).
La scelta finale dipenderà dalle specifiche esigenze del progetto, dalla familiarità del team di sviluppo con determinate tecnologie e dalla strategia a lungo termine per la gestione e la scalabilità dei dati.
tags: #db #non #relazionale #backend #quale #scegliere