La psicometria rappresenta il pilastro metodologico della ricerca in psicologia, occupandosi della teoria e della tecnica della misurazione in questo campo. Il suo ambito di studio abbraccia due aspetti fondamentali: la costruzione di strumenti e procedure adeguate per la misurazione di costrutti psicologici e l'analisi dei dati ottenuti attraverso tali strumenti. L'obiettivo primario del ricercatore psicologo è garantire la corrispondenza tra la realtà indagata e le conclusioni tratte dalla ricerca, controllando attentamente tutti i fattori che potrebbero inficiare tale corrispondenza, inclusa la perdita di soggetti o la mortalità campionaria.

La Misurazione in Psicologia: Costrutti, Variabili e Scale
Al centro della psicometria vi è il concetto di misurazione psicologica, che mira a quantificare caratteristiche astratte e non direttamente osservabili, definite costrutti teorici. Questi costrutti vengono operazionalizzati attraverso variabili, che rappresentano entità misurabili e osservabili. La teoria psicometrica si occupa di definire e sviluppare scale di valutazione che permettano di assegnare valori numerici a tali variabili, riflettendo differenti livelli di intensità o presenza del costrutto.
La costruzione di un test psicologico valido e attendibile è un processo complesso che richiede una solida base teorica e metodologica. Questo processo inizia con un'approfondita teoria di partenza, che si fonda sull'esame della letteratura esistente. Il ricercatore si interroga sui modelli teorici prevalenti, sui metodi di indagine utilizzati, sui punti di forza e di debolezza delle ricerche pregresse, nonché sui problemi ancora irrisolti e sulle lacune conoscitive. Da questa analisi emergono le ipotesi di ricerca, congetture sulle relazioni esistenti tra le variabili considerate. Queste ipotesi possono essere formulate sia sul piano teorico, delineando le relazioni tra oggetti e proprietà, sia sul piano empirico, specificando le relazioni tra casi (unità di analisi) e variabili.
Dalla Popolazione al Campione: Campionamento e Rappresentatività
La ricerca psicologica raramente può avvalersi dell'intera popolazione di interesse a causa di limiti pratici e di risorse. Pertanto, si ricorre al campionamento, una procedura di selezione di un sottoinsieme rappresentativo della popolazione. La rappresentatività del campione è cruciale per poter generalizzare i risultati ottenuti all'intera popolazione. In psicologia, questa rappresentatività è garantita dall'universalità delle proprietà misurate, dall'ampiezza campionaria (in linea con la legge dei grandi numeri) e dal controllo dell'omogeneità per le caratteristiche di interesse.
Esistono diverse strategie di campionamento. Il campionamento probabilistico, come il campionamento casuale semplice, assicura che ogni membro della popolazione abbia una probabilità nota e non nulla di essere incluso nel campione, e che le estrazioni siano indipendenti. Al contrario, il campionamento non probabilistico (o di convenienza/accidentale) non consente di stabilire tali probabilità, basandosi su criteri di accessibilità o disponibilità dei partecipanti. Un esempio di campionamento probabilistico potrebbe essere la selezione casuale di studenti di psicologia da un elenco di iscritti, mentre un campionamento non probabilistico potrebbe coinvolgere studenti reclutati in base alla frequenza a un corso o tramite auto-selezione come volontari.
Strumenti di Misurazione: Test Psicologici e Loro Caratteristiche
Gli strumenti di misurazione in psicologia possono essere selezionati tra quelli già esistenti e validati o costruiti ex novo dal ricercatore. In generale, si prediligono strumenti brevi e di facile comprensione per i partecipanti. Il test è definito come una situazione standardizzata in cui il comportamento di un individuo viene campionato, osservato e descritto, producendo una misura oggettiva e standardizzata.
Il processo di somministrazione di un test prevede la presentazione di stimoli standardizzati che dovrebbero elicitare risposte comportamentali ritenute significative per la misurazione del costrutto in esame. Queste risposte costituiscono un campione delle reazioni che l'individuo manifesterebbe in condizioni simili. Le risposte vengono poi valutate sulla base di criteri standard predefiniti e interpretate in modo univoco come indicatori del costrutto psicologico di interesse.
I test si dividono principalmente in due categorie:
- Test Cognitivi o di Prestazione Massima: Misurano abilità cognitive come intelligenza, attitudine o profitto.
- Test Non Cognitivi o di Prestazione Tipica: Valutano caratteristiche di personalità, atteggiamenti o interessi.
Le tipologie di domande possono essere aperte (richiedono una risposta elaborata) o chiuse (presentano una serie di alternative tra cui scegliere). Nelle domande chiuse, le risposte alternative a quella corretta, dette distrattori, sono formulate graduando la loro plausibilità per rendere la scelta più sfidante. È importante considerare anche i Response Bias, ovvero modalità di risposta che possono falsare sistematicamente i risultati ottenuti.
Un aspetto fondamentale della psicometria è la normatività dei test. Un test normativo utilizza un complesso di norme che ne determinano i criteri di applicabilità e lo rendono idoneo a collocare un individuo, rispetto a una specifica caratteristica psicologica, in relazione a un gruppo di riferimento (gruppo normativo). Queste norme definiscono i criteri per l'interpretazione dei risultati. Esistono anche i Test Criterion-Referenced, che valutano il raggiungimento di un livello o soglia al di sotto della quale si ritiene che la caratteristica in esame non sia posseduta o non sia sufficiente. Esempi di strumenti psicometrici includono i questionari e le Matrici di Raven, queste ultime composte da figure che subiscono trasformazioni geometriche e richiedono la scelta della figura che completa la matrice secondo regole prestabilite.
I test psicologici
Analisi dei Dati e Inferenza Statistica: Verificare le Ipotesi
Una volta raccolti i dati attraverso gli strumenti psicometrici, si procede all'analisi statistica per verificarne le ipotesi di ricerca. Questo processo si articola in diverse fasi, tra cui la verifica delle ipotesi statistiche.
La Verifica delle Ipotesi: Ipotesi Nulla e Alternativa
La verifica delle ipotesi statistiche inizia con la formulazione di due ipotesi contrapposte:
- Ipotesi Nulla (H0): Afferma l'assenza di un effetto o di una differenza. Ad esempio, non c'è differenza tra le medie di due gruppi.
- Ipotesi Alternativa (H1): Afferma la presenza di un effetto o di una differenza, in contrapposizione all'ipotesi nulla.
Il ricercatore, sulla base dei dati campionari, deve decidere se rifiutare o accettare l'ipotesi nulla. Questo processo si avvale di test statistici che calcolano la probabilità di osservare i dati campionari (o dati ancora più estremi) se l'ipotesi nulla fosse vera.
Test Statistici e Valori Critici
Per prendere una decisione, vengono utilizzati diversi test statistici, come il test Z, il test T e il test del Chi Quadrato. Ciascun test è associato a una distribuzione campionaria specifica (ad esempio, la distribuzione normale standardizzata per il test Z). Per valutare la significatività statistica dei risultati, si confronta il valore del test statistico calcolato sul campione con un valore critico determinato dalla distribuzione teorica della statistica test, in corrispondenza di un livello di significatività predefinito (solitamente α = 0.05).
Se il valore del test statistico calcolato è più estremo del valore critico, si rifiuta l'ipotesi nulla in favore dell'ipotesi alternativa. Altrimenti, non si hanno sufficienti evidenze per rifiutare l'ipotesi nulla.
L'Errore Standard e l'Intervallo di Confidenza
Un concetto chiave nella verifica delle ipotesi è l'Errore Standard della Media (SEM), che rappresenta la deviazione standard della distribuzione campionaria delle medie. Esso quantifica la variabilità attesa delle medie campionarie se si estraessero ripetutamente campioni dalla stessa popolazione. Un SEM più basso indica una maggiore precisione della stima della media della popolazione.
L'intervallo di confidenza della media campionaria è un altro strumento fondamentale per l'inferenza statistica. Esso fornisce un range di valori all'interno del quale è probabile che si trovi la vera media della popolazione, con un certo grado di fiducia (ad esempio, un intervallo di confidenza al 95%). La costruzione di questi intervalli si basa sulla media campionaria, sull'errore standard e su valori critici derivati dalle distribuzioni campionarie.
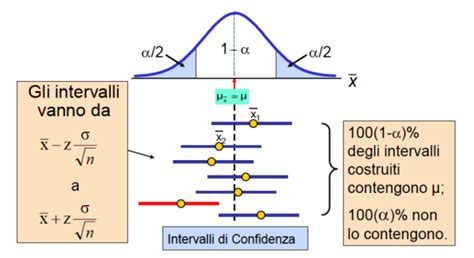
Stima dei Parametri: Puntuale e Intervallare
La stima dei parametri della popolazione (come la media o la deviazione standard) è un altro obiettivo primario dell'inferenza statistica. Si distinguono due approcci:
- Stima Puntuale: Fornisce un singolo valore come migliore approssimazione del parametro della popolazione. La media osservata nel campione è un esempio di stima puntuale della media della popolazione.
- Stima Intervallare: Fornisce un intervallo di valori entro cui si stima si trovi il parametro della popolazione, con un determinato livello di probabilità. L'intervallo di confidenza è l'espressione più comune della stima intervallare.
La scelta tra stima puntuale e intervallare dipende dal grado di precisione desiderato e dalle informazioni disponibili sulla forma della variabile nella popolazione.
Distribuzioni Campionarie: Media, Deviazione Standard e Forma
Le distribuzioni campionarie sono distribuzioni di frequenza delle statistiche calcolate su infiniti campioni estratti da una popolazione. La distribuzione campionaria delle medie, ad esempio, descrive la variabilità attesa delle medie campionarie. I parametri di queste distribuzioni, come la loro media, deviazione standard (che nel caso della distribuzione campionaria delle medie è l'errore standard) e forma, sono fondamentali per l'inferenza statistica.
La forma di una distribuzione campionaria può essere normale o non normale. Il Teorema del Limite Centrale stabilisce che, indipendentemente dalla forma della distribuzione della popolazione, la distribuzione campionaria delle medie tenderà ad assumere una forma normale all'aumentare della dimensione del campione.
Standardizzazione e Punteggi Z: Confrontare e Interpretare
La standardizzazione dei punteggi è una procedura essenziale per confrontare osservazioni provenienti da diverse distribuzioni o per interpretare un punteggio all'interno della propria distribuzione. Il processo di standardizzazione trasforma i punteggi grezzi in punteggi zeta (z-scores).
Il punteggio zeta indica di quante deviazioni standard un particolare punteggio si discosta dalla media della sua distribuzione. Un punteggio z positivo indica che l'osservazione è superiore alla media, mentre un punteggio z negativo indica che è inferiore alla media. Un punteggio z pari a 0 indica che l'osservazione è esattamente uguale alla media.
Le tavole della distribuzione normale standardizzata permettono di determinare la percentuale di casi che ricade al di sotto o al di sopra di un determinato punteggio z, facilitando l'interpretazione della posizione di un punteggio all'interno della sua distribuzione. Ad esempio, conoscendo il punteggio z di un'osservazione, è possibile determinare la probabilità che un'altra osservazione estratta dalla stessa distribuzione sia maggiore o minore di quel valore.
Esempi Pratici di Calcolo e Interpretazione
La comprensione di questi concetti è facilitata dall'analisi di esercizi pratici. Ad esempio, nel determinare la probabilità che un'osservazione cada tra il primo e il terzo quartile in una variabile aleatoria normale, si considera che il range interquartile copre il 50% delle osservazioni.
Considerando una variabile aleatoria normale con media μ e deviazione standard σ, la probabilità che un'osservazione sia inferiore a μ - 2 deviazioni standard (Pr(X ≤ μ - 2)) è pari a 0.159. Di conseguenza, la probabilità che un'osservazione sia inferiore a μ + 2 deviazioni standard (Pr(X ≤ μ + 2)) è pari a 1 - 0.159 = 0.841, poiché la distribuzione normale è simmetrica rispetto alla media. Analogamente, se Pr(X ≤ μ - σ) = 0.159, allora Pr(X ≤ μ + σ) = 1 - 0.159 = 0.841.
Nel caso di una variabile aleatoria uniforme tra 0 e 1, la probabilità che un valore estratto a caso sia esattamente pari a 0.5 è pari a 0, poiché in una distribuzione continua la probabilità di ottenere un singolo valore puntuale è trascurabile.
L'analisi di insiemi di osservazioni permette di calcolare frequenze assolute e relative. Ad esempio, date le osservazioni 3, 5, 2, 6, 3, 5, 5, il numero di osservazioni maggiori o uguali a 5 è 4 (i tre 5 e il 6). La frequenza relativa del valore 3 è 2/7 (due volte il valore 3 su un totale di 7 osservazioni). La frequenza cumulata assoluta del valore 5 include le occorrenze dei valori inferiori (2, 3) più le occorrenze del 5 (2 + 3 = 5). Se però si intende la frequenza cumulata assoluta fino al valore 5, includendo il 5 stesso, allora si contano le occorrenze di 2, 3, e 5, che sono 1 + 2 + 3 = 6.
Se un campione di quattro dati ha media 0 e i primi tre valori sono 3, -2, 1, il quarto valore può essere determinato: (3 + (-2) + 1 + x) / 4 = 0, da cui 2 + x = 0, quindi x = -2.
Nel caso di una distribuzione normale con media μ=100 e deviazione standard σ=10, il primo quartile (Q1) è il valore al di sotto del quale si trova il 25% delle osservazioni. Utilizzando le tavole della distribuzione normale o formule specifiche, si può calcolare che Q1 è circa 93. Se media e mediana sono entrambe 100, ciò indica una distribuzione simmetrica; in questo caso, il primo quartile sarà inferiore alla media.
La media di una distribuzione campionaria di X (0, 0, 0, 1) è (0+0+0+1)/4 = 1/4. La media di X (0, 1, 1, 1) è (0+1+1+1)/4 = 3/4.
Nel contesto dell'analisi delle tabelle di frequenza, la frequenza attesa in caso di indipendenza per una cella si calcola moltiplicando i totali marginali di riga e colonna della cella e dividendo per il totale generale. Per una tabella con totali di riga 50 e 50, e totali di colonna 50 e 50, la frequenza attesa per una cella con totali marginali di 50 e 50 è (50 * 50) / 100 = 25.
La frequenza relativa condizionata della categoria A per il gruppo 1, in una tabella dove il Gruppo 1 ha 20 osservazioni di tipo A e 30 di tipo B (totale 50), è 20/50.
Se in una tabella di frequenza, il Gruppo 1 ha 10 osservazioni di tipo A e 90 di tipo B, mentre il Gruppo 2 ha 100 osservazioni di tipo A e 900 di tipo B, la frequenza relativa di valori A nel Gruppo 1 (10/100 = 0.1) è minore rispetto a quella condizionata al Gruppo 2 (100/1000 = 0.1). In questo caso, sono uguali. Se il Gruppo 1 avesse 10 A e 90 B, e il Gruppo 2 avesse 10 A e 90 B, allora la frequenza relativa di A nel Gruppo 1 sarebbe 10/100 = 0.1, e nel Gruppo 2 sarebbe 10/100 = 0.1, quindi uguali. Se invece il Gruppo 1 avesse 10 A e 90 B, e il Gruppo 2 avesse 100 A e 800 B, la frequenza relativa di A nel Gruppo 1 sarebbe 0.1, mentre nel Gruppo 2 sarebbe 100/900 = 0.111, quindi nel Gruppo 2 sarebbe maggiore.
Se una tabella di frequenza assoluta su 50 osservazioni valide presenta 10 in A e 20 in B, la frequenza della cella C sarà 50 - 10 - 20 = 20.
Considerando tabelle di frequenza, una statistica X² (Chi Quadrato) elevata suggerisce una forte associazione tra le variabili categoriche, indicando che le frequenze osservate si discostano significativamente da quelle attese in caso di indipendenza. Al contrario, un valore di X² prossimo a 0 suggerisce indipendenza. Una statistica X elevata può indicare una forte relazione, mentre un valore prossimo a zero suggerisce una relazione debole o assente.
Trasformazione in Punteggio Z
La trasformazione in punto Z è fondamentale per confrontare osservazioni da distribuzioni diverse. Se un'osservazione x = 17 proviene da una variabile aleatoria normale con media μ=15, il punteggio z sarà positivo (z = (17-15)/σ = 2/σ). Poiché la deviazione standard σ è sempre positiva, z sarà positivo. Se x=15 e μ=17, allora z = (15-17)/σ = -2/σ, quindi il punteggio Z sarà negativo.
Se un'unità statistica ha un punto z pari a 0.5, significa che la sua osservazione è superiore alla media, e si trova a metà strada tra la media e un valore che è una deviazione standard sopra la media. In una distribuzione normale, un punteggio z di 0.5 corrisponde a una probabilità cumulativa di circa 0.6915. Ciò implica che circa il 69.15% delle osservazioni della popolazione è inferiore a questo valore, quindi oltre la metà delle osservazioni della popolazione è inferiore all'unità considerata.
Nel confronto tra due distribuzioni, ad esempio X e Y, se la distribuzione di X è spostata verso valori più bassi rispetto a Y (ad esempio, ha una media inferiore), allora la probabilità che un'osservazione di X sia minore o uguale a un certo valore (es. -1) sarà minore della probabilità che un'osservazione di Y sia minore o uguale allo stesso valore. Quindi, Pr(X ≤ -1) < Pr(Y ≤ -1).
Probabilità e Eventi: Fondamenti per l'Inferenza
La teoria della probabilità fornisce le basi per l'inferenza statistica. Due eventi E1 e E2 sono detti esclusivi se non possono verificarsi contemporaneamente, come nel caso di ottenere un 3 o un 4 nel lancio di un singolo dado. Se vale Pr(E1 U E2) = Pr(E1) + Pr(E2), i due eventi sono esclusivi.
La probabilità di ottenere un solo numero pari nel lancio di due dadi è la somma delle probabilità dei seguenti eventi mutuamente esclusivi: (pari, dispari) o (dispari, pari). La probabilità di un numero pari è 1/2, e di un numero dispari è 1/2. Quindi, P(pari, dispari) = 1/2 * 1/2 = 1/4. P(dispari, pari) = 1/2 * 1/2 = 1/4. La probabilità totale è 1/4 + 1/4 = 1/2.
La probabilità di ottenere almeno un numero pari nel lancio di due dadi può essere calcolata come 1 meno la probabilità di ottenere due numeri dispari: 1 - (1/2 * 1/2) = 1 - 1/4 = 3/4.
I risultati del lancio di un dado e del lancio di una moneta sono eventi indipendenti, poiché l'esito di uno non influenza l'esito dell'altro. Allo stesso modo, il lancio di un dado e l'estrazione casuale di una carta da un mazzo sono azioni indipendenti.
Pierino ha due numeri fortunati: 3 e 5. La probabilità di ottenere un numero sia pari che fortunato nel lancio di un dado (equilibrato) a sei facce è 0, poiché né il 3 né il 5 sono numeri pari.
La probabilità di ottenere un numero che sia pari o maggiore di 2 nel lancio di un dado è:Pari: {2, 4, 6}Maggiore di 2: {3, 4, 5, 6}Unione (Pari o Maggiore di 2): {2, 3, 4, 5, 6}. Ci sono 5 numeri favorevoli su 6. La probabilità è 5/6.
Se si sa che il lancio di un dado equilibrato a sei facce ha realizzato un valore maggiore di 3 ({4, 5, 6}), la probabilità che questo sia pari ({4, 6}) è 2/3.
Il numero di facce 6 nel lancio di 100 dadi (equilibrati) è un processo casuale descritto da una variabile aleatoria Binomiale con parametri n=100 (numero di prove) e p=1/6 (probabilità di successo in ogni prova).
Correlazione e Rappresentazioni Grafiche
Il coefficiente di correlazione quantifica la forza e la direzione della relazione lineare tra due variabili. Un coefficiente di correlazione di +0.95 indica una forte relazione lineare positiva, suggerendo che all'aumentare di una variabile, aumenta anche l'altra. Al contrario, un coefficiente di -0.9 indica una forte relazione lineare negativa. Un coefficiente di +0.01 suggerisce una relazione lineare molto debole.
Il coefficiente di correlazione di Spearman si basa sui ranghi delle osservazioni ed è utile quando la relazione non è strettamente lineare o quando si hanno dati ordinali. Un coefficiente di Spearman di +0.9 indica una forte concordanza nei ranghi.
Interpretazione di Grafici Statistici
L'interpretazione di grafici statistici come grafici di dispersione, istogrammi e boxplot è fondamentale per comprendere la distribuzione dei dati e le relazioni tra variabili.
In un istogramma, la posizione della media e della mediana fornisce informazioni sulla simmetria della distribuzione. Se la media è maggiore della mediana (come nel caso di una media di 2.97 e una mediana più bassa, ad esempio 2.318), la distribuzione è asimmetrica a destra (positivamente asimmetrica). Se la media è minore della mediana, la distribuzione è asimmetrica a sinistra (negativamente asimmetrica). In una distribuzione normale, media e mediana coincidono.
Un boxplot rappresenta la distribuzione dei dati attraverso i quartili, la mediana e gli estremi, fornendo una sintesi visiva della dispersione e della simmetria. Confrontando un istogramma con diversi boxplot, è possibile identificare quale boxplot rappresenta gli stessi dati, prestando attenzione alla mediana, al range interquartile e ai valori estremi.
La distribuzione della soddisfazione della clientela di una gelateria, rappresentata graficamente, permette di individuare la mediana. La mediana divide la distribuzione in due parti uguali, quindi cade nella modalità che separa il 50% inferiore dal 50% superiore delle osservazioni. Se la mediana cade nella modalità "Molto Soddisfatto", significa che almeno il 50% dei clienti è "Molto Soddisfatto" o più.
tags: #appunti #psicometria #psicologia