I database relazionali rappresentano la spina dorsale di innumerevoli applicazioni e sistemi informativi moderni. La loro capacità di organizzare, archiviare e recuperare dati in modo strutturato ed efficiente li rende indispensabili per aziende di ogni dimensione. Al centro di questa gestione dei dati si trova SQL (Structured Query Language), il linguaggio standard de facto per l'interazione con i database relazionali. La sua evoluzione, le sue funzionalità e la sua integrazione con altri linguaggi di programmazione sono fondamentali per comprendere appieno il panorama attuale della gestione dei dati.
Le Origini e l'Evoluzione di SQL
SQL nasce nel 1974 ad opera di Donald Chamberlin, nei laboratori dell'IBM. Fu concepito come uno strumento per lavorare con database che seguissero il modello relazionale, un paradigma rivoluzionario proposto da Edgar F. Codd, anch'egli ricercatore IBM, che prevedeva l'organizzazione dei dati in tabelle interconnesse. Originariamente, il linguaggio si chiamava SEQUEL, acronimo di Structured English Query Language, da cui deriva la pronuncia IPA corretta di SQL: /ɛskjuːˈɛl/, sebbene la pronuncia informale /ˈsiːkwəl/ sia anch'essa diffusa.
Nel 1975, venne sviluppato un prototipo chiamato SEQUEL-XRM. Le sperimentazioni condotte con questo prototipo portarono, nel 1977, a una nuova versione del linguaggio. Inizialmente prevista come SEQUEL/2, per motivi legali legati all'uso registrato del nome SEQUEL da parte di una compagnia aerea, la nuova versione divenne semplicemente SQL. Su questa base, IBM sviluppò il prototipo System R, utilizzato internamente e con alcuni clienti.
Il successo di SQL fu immediato e altre società iniziarono a sviluppare i propri prodotti basati su di esso. IBM iniziò a commercializzare prodotti relazionali nel 1981 e, nel 1983, pubblicò DB2, un RDBMS (Relational Database Management System) che avrebbe guadagnato ampia diffusione.
L'adozione di SQL come standard da parte dell'ANSI (American National Standards Institute) nel 1986, senza modifiche sostanziali alla versione IBM, segnò un passaggio cruciale. La ISO (International Organization for Standardization) seguì l'esempio nel 1987. Queste prime versioni standardizzate, denominate SQL/86, furono seguite da SQL/89, SQL/92 e SQL/2003, in un continuo processo di standardizzazione volto a creare un linguaggio universale per i DBMS relazionali, obiettivo che, pur non essendo mai stato pienamente raggiunto, ha comunque garantito un'elevata interoperabilità.

Cos'è un Database Relazionale?
Prima di addentrarci nella tecnologia e nelle spiegazioni, cerchiamo prima di capire che cosa si intende per database. Immaginatelo come un programmino, uno strumento che consente facilmente di gestire i dati di un determinato progetto. I database si utilizzano in tantissimi casi diversi: all'interno di un'app, all'interno di siti internet, nei software; essenzialmente, queste competenze sono richieste in maniera trasversale in tanti campi diversi.
Un database relazionale è un tipo di database che organizza i dati in tabelle, strutturate con righe e colonne. Ogni tabella, detta anche relazione, rappresenta una persona o un'idea specifica. Le righe di una tabella rappresentano i singoli record e le colonne i dettagli di tali record. I database relazionali offrono un modo strutturato ed efficiente per memorizzare, recuperare e gestire grandi volumi di dati. Assicurano l'integrità e la coerenza dei dati attraverso le relazioni tra le tabelle e l'uso di chiavi primarie ed esterne.
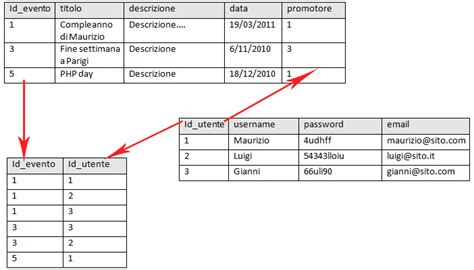
Se un'organizzazione impiega tempo e denaro nel tentativo di setacciare un'infinità di dati, potrebbe essere il candidato ideale per un database relazionale. Per vedere la potenza di un modello di dati relazionale, non serve guardare oltre il versatile foglio di calcolo. Se vi sentite a vostro agio nell'usare i fogli di calcolo per ordinare le righe di dati, avete già un'idea del perché i modelli di database relazionali siano così efficaci. Allo stesso modo, i database relazionali funzionano dividendo diverse forme di dati in tabelle intuitive per strutturare le informazioni. Forniscono un modo standard di rappresentare e interrogare i dati che può essere utilizzato da qualsiasi applicazione.
Ad esempio, un'azienda che si occupa di cura della pelle può avere diverse tabelle dedicate ai diversi clienti e ai loro ordini. Queste tabelle possono riguardare la quantità di ordini o di clienti che acquistano un prodotto specifico e sono composte da righe e colonne (note anche come record e attributi, rispettivamente). Ogni riga avrà un record unico, mentre ogni colonna avrà un attributo specifico. Per continuare la metafora di cui sopra, un'azienda di prodotti per la cura della pelle ha una tabella dedicata a più clienti. La tabella potrebbe avere colonne che indicano l'attività di acquisto di prodotti per l'acne, l'eczema e la pelle secca.
I database relazionali sono praticamente la base, vengono utilizzati nel 95% dei progetti. La struttura dei database relazionali si adatta molto facilmente alla maggior parte delle problematiche che possono insorgere. Cosa succede quando pubblichi una foto? Quella foto viene salvata in una tabella che contiene tutte le foto salvate di tutti gli utenti. Quando un altro utente commenta la tua foto, ci sarà un'altra tabella che contiene tutti i commenti, e in questa tabella ci sarà il riferimento alla tua foto e dell'utente che l'ha appena commentata. Quindi, ricapitolando, abbiamo due tabelle e una foto può ricevere più commenti. Quando pensiamo a un database relazionale, dobbiamo innanzitutto immaginarci quali tabelle servono per poter far funzionare la nostra applicazione. Ecco perché si chiamano database relazionali.
Non esiste solo un tipo di database relazionale, ma ce ne sono tanti. I più comuni sono MySQL, SQL Server e PostgreSQL. In generale, la cosa importante da capire di tutte queste tecnologie della famiglia dei database relazionali è che c'è una costante: il linguaggio SQL.
SQL: Un Linguaggio Dichiarativo per la Gestione dei Dati
SQL è un linguaggio per interrogare e gestire basi di dati mediante l'utilizzo di costrutti di programmazione denominati query. Con SQL si leggono, modificano, cancellano dati e si esercitano funzioni gestionali e amministrative sul sistema dei database. Originariamente progettato come linguaggio di tipo dichiarativo, si è successivamente evoluto con l'introduzione di costrutti procedurali, istruzioni per il controllo di flusso, tipi di dati definiti dall'utente e varie altre estensioni del linguaggio.
Essendo un linguaggio dichiarativo, SQL non richiede la stesura di sequenze di operazioni (come ad esempio i linguaggi imperativi), ma piuttosto di specificare le proprietà logiche delle informazioni ricercate.
Categorie di Istruzioni SQL
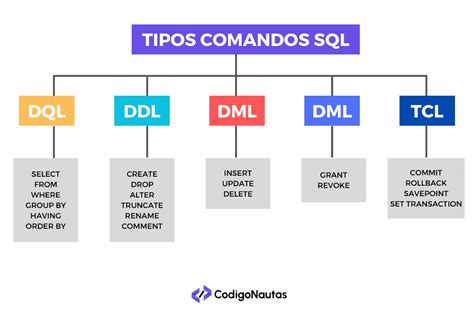
Le istruzioni SQL sono suddivise in diverse categorie, ciascuna con uno scopo specifico:
- DDL (Data Definition Language - Linguaggio di Definizione dei Dati): Serve a creare, modificare o eliminare gli oggetti in un database. Sono i comandi DDL a definire la struttura del database e quindi dei dati ivi contenuti. Comandi tipici includono
CREATE TABLE,ALTER TABLE,DROP TABLE. - DML (Data Manipulation Language - Linguaggio di Manipolazione dei Dati): Fornisce i comandi per inserire, modificare ed eliminare dati all'interno delle tabelle di un database. La struttura di questi dati deve già essere stata definita tramite il DDL. Comandi tipici includono
INSERT,UPDATE,DELETE. - DQL (Data Query Language - Linguaggio di Interrogazione dei Dati): Comprende i comandi per leggere ed elaborare i dati presenti in un database. Il comando principale è
SELECT. - DCL (Data Control Language - Linguaggio di Controllo dei Dati): Controlla l'accesso ai dati tramite comandi come
GRANT(per concedere le autorizzazioni) eREVOKE(per rimuovere le autorizzazioni). - TCL (Transaction Control Language - Linguaggio di Controllo delle Transazioni): Gestisce le modifiche alle transazioni per contribuire a garantire l'integrità dei dati e supporta le operazioni
ROLLBACK(annullare) eCOMMIT(salvare) per le modifiche.
Operatori e Espressioni in SQL
Gli operatori di confronto servono a determinare uguaglianze e disuguaglianze tra valori e a effettuare ricerche all'interno dei dati. Esempi includono =, !=, <, >, <=, >=.
Gli operatori aritmetici accettano operatori di un tipo numerico (interi o decimali) e restituiscono il risultato dell'operazione aritmetica corrispondente. Sebbene lo standard SQL non preveda questa famiglia di operatori, essa è presente in molte implementazioni.
Un'espressione è costituita da un valore o da un'operazione che restituisce un valore. Questa definizione è ricorsiva: le espressioni possono essere annidate. L'uso delle parentesi tonde all'interno delle espressioni di ricerca consente di modificare o esplicitare la precedenza degli operatori, ossia l'ordine in cui essi vengono elaborati.
Operatori di Pattern Matching
Per effettuare ricerche più flessibili, SQL offre operatori di pattern matching:
- LIKE: Utilizzato con wildcard per trovare stringhe che corrispondono a un pattern specifico.
- Wildcard:
- Il carattere underscore (
_) esegue la ricerca su un singolo carattere arbitrario. - Il simbolo percentuale (
%) è detto operatore jolly ed esegue la ricerca su una stringa arbitraria, ovvero su un intervallo di valori numerici.
- Il carattere underscore (
La sintassi di Microsoft Access è leggermente diversa dallo standard internazionale. Invece del simbolo underscore, si utilizza ? per ricercare un singolo carattere (sia numero che lettera); invece del simbolo %, l'operatore jolly è dato da *. Access permette di ricercare un singolo valore numerico tramite il tasto hash (#), e di ricercare un carattere (lettera e numero) all'interno o all'esterno di un insieme di valori, con la sintassi [] e [! ]. L'intervallo può essere puntuale o collettivo: ad esempio, [A-F] indica le lettere comprese fra A ed F, mentre [A, F] indica solo la ricerca di queste due lettere. Ad esempio, un'istruzione come 'LIKE P[!A-F]C' ricerca le parole che iniziano per "P", finiscono per "C" e per seconda lettera non hanno i caratteri compresi fra le lettere A e F.
- SIMILAR TO: Parte dello standard SQL, consente di verificare se una stringa corrisponde a una data espressione regolare.
- REGEXP: Più diffuso e anch'esso consente di verificare se una stringa corrisponde a una data espressione regolare.
Gestione dei Dati e Transazioni
Il DML (Data Manipulation Language) è il cuore dell'interazione con i dati.
- INSERT: Di per sé, il comando
INSERTopera inserendo in tabella una sola riga per volta. Le colonne di destinazione dei valori possono essere o meno dichiarate nel comando. Se non vengono dichiarate, è necessario passare al comando un valore per ogni colonna della tabella, rispettando rigorosamente l'ordine delle colonne stesse. - UPDATE: Il comando generico
UPDATEaggiorna tutte le righe della tabella, a meno che non venga specificata una clausolaWHEREper limitare l'operazione a righe specifiche. - DELETE: Una
DELETEpriva di clausolaWHEREcancella tutte le righe dalla tabella specificata. Tuttavia, esiste un altro modo per svuotare completamente una tabella: il comandoTRUNCATE TABLE. Alcuni DBMS implementano questo comando (che non è presente nello standard SQL) in modo più veloce rispetto a unaDELETE, ad esempio cancellando il file dei dati senza leggerlo e ricreandolo vuoto.
Transazioni in SQL
Una transazione è un blocco di istruzioni che sono strettamente correlate tra loro. Nel caso in cui, per qualsiasi motivo (un errore interno al DBMS, un errore nelle istruzioni SQL, un errore di sistema), una delle istruzioni non arrivi a compimento, l'intera transazione verrà annullata. Si dice quindi che una transazione è un'operazione atomica, ossia non è divisibile: se non viene eseguita interamente, non verrà eseguita affatto.
Fino a quando una transazione non ha esito positivo, le modifiche che apporta sono visibili solo per la sessione che ha avviato la transazione. Non tutti i DBMS supportano le transazioni, mentre altri le supportano solo in determinate condizioni (ad esempio, in MySQL sono supportate solo per alcuni tipi di tabelle). Alcuni DBMS inoltre consentono le transazioni annidate.
Un'alternativa semanticamente molto simile è costituita dai savepoint. Essi consentono di salvare una versione dei dati nel mezzo di una transazione. Sarà poi possibile annullare l'intera transazione oppure ripristinare uno dei savepoint precedentemente impostati.
- Per iniziare esplicitamente una transazione si utilizza il comando
BEGIN TRANSACTION. - Per confermare la transazione si utilizza il comando
COMMIT. - Per annullare la transazione si utilizza il comando
ROLLBACK.
Funzionalità Avanzate e Subquery
Il DQL (Data Query Language) è fondamentale per estrarre informazioni dai database.
- LIMIT (o TOP): A seconda delle implementazioni,
LIMIT(oTOP) limita il numero delle righe fornite. Ad esempio,LIMIT 10prende le prime dieci righe di una tabella. Alcuni sistemi permettono anche di specificare la posizione della prima riga da estrarre (numero_risultatiepos_primo_risultato).
Subquery in SQL
Le subquery (o sottoquery) possono essere inserite ovunque il linguaggio SQL ammetta un'espressione che restituisce un singolo valore e nella clausola FROM. Le subquery propriamente dette possono restituire un singolo valore, oppure un insieme di risultati, a seconda dei casi.
Un esempio didattico, sebbene non sempre l'approccio più ottimale, è quello in cui si vogliono estrarre da una tabella i valori numerici superiori alla media. Una sola SELECT non può leggere la media e al contempo i valori che la superano. In questi casi, una subquery può essere utilizzata per calcolare la media in una prima fase, per poi utilizzarla nella query principale.
Estensioni di SQL e Linguaggi Complementari
SQL è un linguaggio di interrogazione pensato per interagire con i database relazionali. Tuttavia, i teorici fanno notare come le caratteristiche originali dell'SQL, ispirate al calcolo delle tuple, in realtà lo violino.
Stored Programs e Business Logic
Con il termine Stored Programs, o Business Logic, si intendono quelle routine programmate in SQL, con le estensioni procedurali che permettono il controllo del flusso, i cicli, i cursori e la gestione degli errori. Queste estensioni rendono SQL un linguaggio più potente, capace di incapsulare logiche applicative complesse direttamente all'interno del database.
Linguaggi Complementari a SQL
SQL è un linguaggio moderno e ampiamente utilizzato che trova applicazione in quasi tutti i settori. Non c'è carenza di posti di lavoro con SQL. Tuttavia, acquisire competenze in un altro linguaggio di programmazione non può che migliorare l'occupabilità e aumentare la gamma di ruoli per i quali ci si può candidare.
Analizza le prestazioni del negozio con Python + SQL | Progetto per principianti di Real Data (pa...
Python: Python e SQL sono una combinazione perfetta. Python è uno dei linguaggi di scripting più diffusi al mondo, uno dei più facili da imparare e uno dei migliori per l'analisi e la visualizzazione dei dati. SQL non è progettato per la manipolazione dei dati ad alto livello (come regressioni, serie temporali e analisi statistiche). Per questo motivo, Python è un ottimo linguaggio partner se si desidera eseguire questo tipo di operazioni. Python rende inoltre molto più semplice e veloce l'esplorazione di diversi percorsi, che può portare a scoprire molto più di quanto si farebbe con un approccio SQL puro.
R: R e SQL sono alleati da sempre. R è un linguaggio di programmazione e un ambiente software per il calcolo statistico e la grafica. R supporta il recupero di dati da database relazionali centralizzati utilizzando SQL, il che significa che la relazione tra i due è ben consolidata. In R sono disponibili diversi pacchetti che consentono agli utenti di creare e interrogare insiemi di dati e contemporaneamente di elaborarli e analizzarli. Pacchetti come RSQLite aiutano gli utenti a recuperare i dati da file e fogli di calcolo per inserirli in un database accessibile con SQL. Il pacchetto
sqldfsemplifica ulteriormente le cose, consentendo agli utenti di utilizzare SQL sui frame di dati e di eliminare completamente la necessità di configurare qualsiasi tipo di database. Una conoscenza anche minima di R può essere molto utile per l'apprendimento dei database e per la creazione di una carriera nell'amministrazione dei database e nell'analisi dei dati.
Analizza le prestazioni del negozio con Python + SQL | Progetto per principianti di Real Data (pa...
Java: Java ha mantenuto la sua posizione di linguaggio di programmazione popolare e potente per più di due decenni. Anche se Java non è la prima scelta di un analista di dati come linguaggio di programmazione, non significa che non sarà utile. Se poi si aggiunge la conoscenza di SQL, si è in grado di integrare le attività di database nel proprio lavoro di sviluppo. L'API JDBC (Java Database Connectivity) consente di connettersi al database MySQL con Java e recuperare dati per utilizzarli nel proprio lavoro di codifica Java.
C#: Come Java, C# è un linguaggio di programmazione popolare con applicazioni specifiche, come la creazione di siti web e applicazioni Windows. C# e altri linguaggi .Net possono lavorare con la maggior parte dei database, ma più comunemente con Oracle e Microsoft SQL Server. Esistono modi semplici per collegare C# a SQL, permettendo ai due linguaggi di lavorare insieme.
Power BI: Sebbene non sia un linguaggio di programmazione, Power BI si abbina a SQL. Power BI è un servizio di analisi aziendale di Microsoft basato sul cloud che aiuta gli utenti a visualizzare e analizzare meglio i dati. Offre funzionalità come il data warehousing e il data discovery ed è in grado di caricare un'ampia gamma di visualizzazioni personalizzate. È stato riconosciuto come strumento leader nel mondo dell'analisi e della business intelligence da Gartner per 12 anni consecutivi.
Database Relazionali vs. Non Relazionali
Mentre i database relazionali sono la norma per molte applicazioni, esistono anche i database non relazionali (talvolta chiamati database NoSQL).
I database relazionali sono fortemente strutturati e presentano un'elevata integrità dei dati. Questi database sono molto efficaci nel garantire che i dati non vengano duplicati, persi o utilizzati in modo improprio. Garantiscono alle aziende un elevato livello di sicurezza e offrono tempi di risposta molto rapidi. I database relazionali utilizzano anche uno schema fisso. Per qualsiasi applicazione che richieda un elevato volume di query o transazioni complesse, sono i più adatti.
Un database non relazionale, invece, è meno strutturato. Questo approccio li rende flessibili e scalabili per le aziende che crescono troppo velocemente per poter avere limitazioni. I database non relazionali memorizzano i dati in vari formati, come coppie chiave-valore, documenti, archivi a colonne larghe o grafici, a seconda del tipo specifico di database NoSQL. Questa flessibilità consente loro di gestire in modo efficiente dati non strutturati o semi-strutturati. A differenza dei database relazionali, i database NoSQL possono facilmente scalare orizzontalmente, aggiungendo altri server per gestire carichi crescenti, il che li rende ideali per applicazioni di dati su larga scala.

Se si vuole iniziare con i database, è consigliabile partire dai database relazionali, in quanto sono molto richiesti nel mercato del lavoro dal momento che si adattano alla maggior parte delle problematiche dei progetti.
Software per la Gestione di Database
Esistono numerosi software per la creazione e la gestione di database, che variano per complessità, funzionalità e costo:
Programmi Gratuiti:
- LibreOffice Base: Parte della suite d'ufficio gratuita e open-source LibreOffice, è un'alternativa valida per la gestione di database relazionali.
- Apache OpenOffice Base: Simile a LibreOffice Base, è il gestore di database della suite Apache OpenOffice.
- MariaDB: Un server di database relazionale open-source, spesso utilizzato da utenti esperti e gestito dalla riga di comando.
Programmi Professionali:
- Microsoft Access: Incluso nella suite Microsoft Office, è uno strumento potente per la gestione di database relazionali, ideale per utenti Windows.
- Claris FileMaker: Una soluzione completa per creare, gestire e manipolare vari tipi di database, anche se a pagamento.
- Ninox Database: Un software per macOS semplice da usare, in grado di creare app aziendali e database su misura.
Programmi per Database SQL:
- XAMPP con phpMyAdmin: XAMPP è una distribuzione gratuita che include un server web Apache, un server di database MySQL e PHP. phpMyAdmin è un'interfaccia web che consente di gestire facilmente i database MySQL e manipolarli tramite SQL.
App per Tablet (iPad e Android):
- Airtable: Un gestore di database versatile e facile da usare, disponibile per dispositivi mobili.
Vantaggi e Svantaggi dei Database Relazionali
I database relazionali sono una risorsa incredibile per le aziende grazie all'efficacia con cui memorizzano e organizzano i dati. Le aziende possono ottenere una conoscenza più approfondita dei loro clienti, aiutandoli a prendere decisioni più intelligenti.
Vantaggi:
- Integrità dei Dati: Garantiscono che i dati siano sempre accurati e coerenti in tutto il database. L'integrità referenziale mantiene le relazioni logiche tra le tabelle.
- Flessibilità delle Query: Grazie a SQL, è possibile eseguire query complesse che possono unire più tabelle, aggregare dati e filtrare i risultati.
- Scalabilità: Sono in grado di gestire volumi di dati molto grandi e numerosi utenti contemporaneamente.
- Sicurezza: Offrono un livello di sicurezza elevato con sistemi di controllo degli accessi granulari e funzioni di crittografia.
- Indipendenza dei Dati: Offrono indipendenza dei dati logici e fisici, garantendo flessibilità nella gestione del database.
- Standardizzazione: L'adozione di SQL come standard garantisce un'ampia compatibilità e un vasto ecosistema di strumenti e risorse.
Svantaggi:
- Schema Complesso: Richiedono un'attenta pianificazione per funzionare efficacemente.
- Non Ottimizzati per Dati Non Strutturati: Non sono ideali per l'archiviazione e l'interrogazione di dati non strutturati.
- Scalabilità Verticale: Sebbene scalabili, tendono a scalare verticalmente (aumentando le risorse di una singola macchina) più che orizzontalmente, il che potrebbe non essere ideale per tutte le esigenze di crescita rapida.
- Vulnerabilità a SQL Injection: Se non adeguatamente protetti, i database SQL possono essere vulnerabili ad attacchi di SQL injection.
In sintesi, SQL è uno dei linguaggi di programmazione più importanti e diffusi al mondo utilizzato per la gestione e l'interrogazione di database relazionali. La sua standardizzazione ha permesso la sua diffusione a livello globale e la sua versatilità lo rende uno strumento molto potente per l'analisi e la gestione dei dati.
tags: #linguaggio #programmazione #database #relazionale